Improving DeepEP MoE Load Balance in SGLang with Waterfill and LPLB
TL;DR
Mixture-of-Experts (MoE) models rely on Expert Parallelism (EP) to scale inference across multiple GPUs. In SGLang, DeepEP and EPLB provide high-performance serving under EP, but the workload seen by each rank can still be imbalanced because tokens are not routed uniformly across experts.
This blog introduces two dispatch-time load balancing features in SGLang:
- Waterfill, a lightweight shared-expert load balancing method for DeepEP. It dispatches the shared expert through DeepEP and assigns it to less-loaded ranks. On two Hopper GPU nodes with DeepSeek-V3/R1-style serving workloads, Waterfill improves total throughput by +1.48% to +4.66% across MMLU, GPQA, and GSM8K. On DeepSeek V4, the best measured point improved from 49,253 tok/s to 51,677 tok/s (+4.92%).
- LPLB, a linear-programming-based load balancer for redundant expert replicas. It solves a per-layer dispatch optimization problem over redundant experts. With redundant EPLB placement on the same two Hopper GPU nodes, LPLB improves total throughput by +0.84% to +7.34% across MMLU, GPQA, and GSM8K.
The Waterfill work is built on two SGLang PRs: shared expert fusion under EP and Waterfill dispatch balancing. DeepSeek V4 support is added in #25391. LPLB is introduced in #24515.
Introduction
Large MoE models such as DeepSeek-V3/R1 and DeepSeek V4 use sparse expert activation to increase model capacity while keeping per-token computation manageable. During inference, EP distributes experts across GPUs and routes tokens to the ranks that own the selected experts. This reduces per-GPU memory pressure and makes large-scale serving practical, but it also introduces a central systems problem: the router does not generate perfectly balanced expert traffic.
When some experts receive many more tokens than others, the EP group waits for the busiest ranks. This imbalance affects both computation and communication. Static placement methods such as EPLB can improve the long-term placement of experts and redundant replicas, but a single batch can still have residual imbalance. Dispatch-time load balancing addresses this remaining gap by deciding, at runtime, which physical replica should process each token or each shared-expert request.
In SGLang, we have been working on two dispatch-time approaches for DeepEP MoE inference:
- Waterfill: a low-overhead algorithm focused on the shared expert path.
- LPLB: an LP-based algorithm focused on token routing across redundant expert replicas.
The two algorithms target the same broad layer of the system: dispatch-time MoE load balancing. They make different tradeoffs and operate on different dispatch choices.
Background: Load Imbalance in DeepEP MoE Inference
DeepEP accelerates MoE inference by providing optimized token dispatch and combine kernels for expert parallelism. In a typical DeepSeek-style MoE layer, each token is routed to several routed experts selected by the model router. Some models also include a shared expert, which is applied to every token.
From a serving-system perspective, routed experts and shared experts create different load patterns:
- Routed experts are sparse. Different tokens choose different experts, so their load depends on the router distribution.
- Shared experts are dense. Every token needs the shared expert, so the shared-expert workload is present for the full batch.
- Redundant experts, introduced by EPLB-style placement, provide multiple physical replicas for some logical experts. They create an opportunity for dispatch-time balancing, because the system can choose which physical replica processes a token without changing the model's logical expert choice.
Static expert placement is helpful, but it cannot remove all runtime imbalance. The actual tokens in a batch may still concentrate on a subset of experts or ranks. In DeepEP, this can leave some ranks waiting for overloaded peers. Waterfill and LPLB both aim to reduce this dispatch-time imbalance while preserving the model's semantics.
Waterfill: Lightweight Load Balancing for Shared Expert Dispatch
Waterfill Dispatch Strategy
Waterfill is a lightweight load balancing algorithm for the shared expert path under DeepEP.
If the shared expert is always computed locally on every rank, then each rank pays the shared-expert cost regardless of whether it is already overloaded by routed experts. The overloaded ranks remain overloaded, and the less-loaded ranks cannot help absorb the shared-expert work.
Waterfill changes this by treating the shared expert as a dispatchable expert slot. After the routed experts are selected, Waterfill estimates the current routed load on each EP rank, then assigns the shared expert work to ranks with lower load. Conceptually, it fills the valleys in the rank-load distribution, similar to pouring water into uneven containers.
For each token, Waterfill adds one extra expert slot for the shared expert. Instead of always assigning that slot to the token's local rank, it selects a rank based on the current load distribution. This keeps the routed expert choices unchanged, so the model still computes the same logical routed experts and the same shared expert. The only thing that changes is which physical rank executes the shared expert work.
At a high level, the algorithm is:
-
Count the routed expert load already landing on each EP rank.
-
Use that count as a per-rank load score. In dynamic mode, SGLang first runs one EP-group collective, so the score can use the global routed-load vector plus each rank's current local batch size.
-
Add one shared-expert slot per participating token, and compute a target waterline:
Here is rank 's load score, is the number of shared-expert slots to place, and is the EP group size.
-
Ranks below this waterline have slack:
-
For each token, Waterfill samples the shared-expert target rank from candidate ranks with probability proportional to slack, with a small local-rank preference. If all candidates have zero slack, it falls back to the clearly lighter candidate rank, again keeping the local-rank preference.
The detailed derivation and the exact SGLang static/dynamic behavior are documented in the Waterfill dispatch balancing PR.
There is an important communication tradeoff. If every token could send its shared-expert work to any EP rank, Waterfill would have more balancing freedom, but it could also increase all-to-all traffic. For GPU MoE serving, communication is often more expensive than the extra shared-expert computation. The communication-conservative candidate set therefore keeps the shared expert on ranks that the token already visits for routed experts, with the source rank kept as a fallback. SGLang also supports an all-rank mode, which gives Waterfill more balancing freedom but can add a new per-token dispatch destination. This is a deliberate communication tradeoff rather than a change in model semantics.
By shifting shared-expert work away from already-heavy ranks and toward lighter ranks, Waterfill balances per-rank work and improves end-to-end throughput.
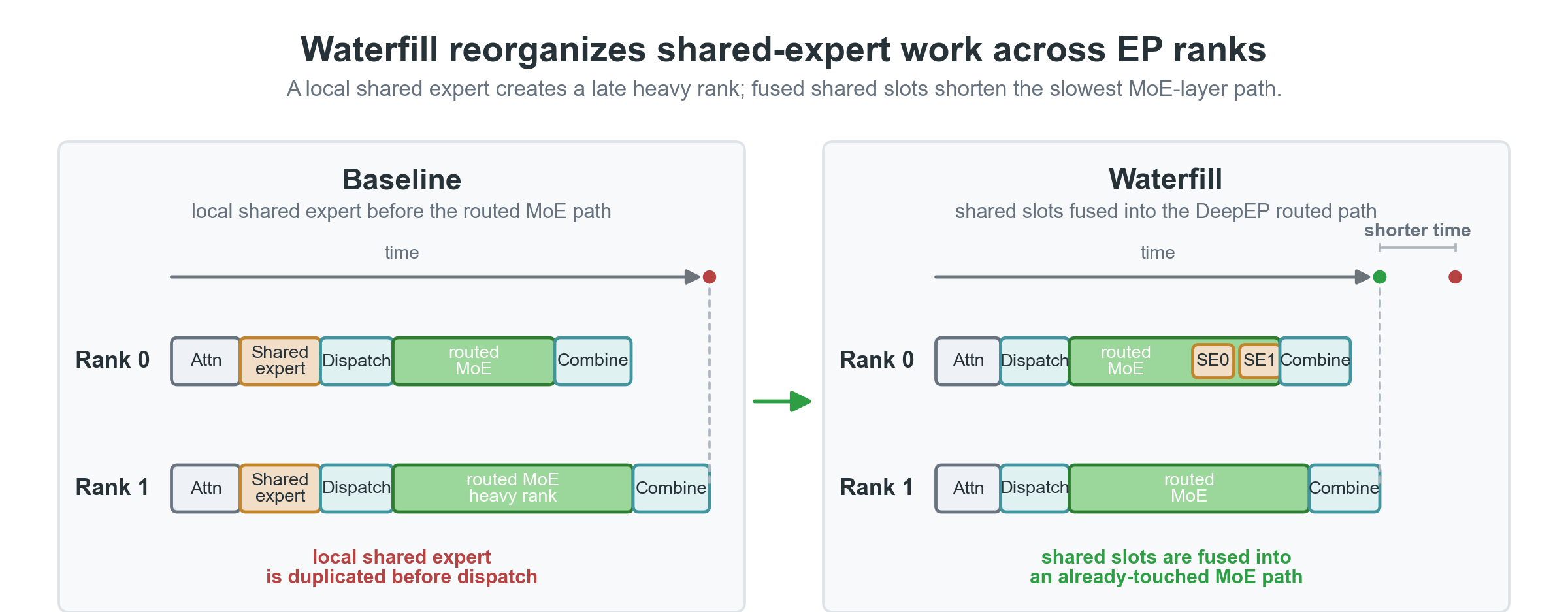
Figure 1. Waterfill moves shared-expert work from overloaded ranks to lighter ranks while keeping the routed expert choices unchanged, shortening the slowest MoE-layer path without changing model semantics.
Shared Expert Fusion as the Enabling Mechanism
Waterfill can be further accelerated by fusing shared experts and routed experts.
Under EP, shared experts used a separate execution path from the routed experts. After Waterfill chooses non-local shared-expert ranks, that design would need to extract shared-expert tokens from the dispatched routed-expert layout and launch a separate shared-expert computation, adding extra layout conversion and launch overhead.
Shared expert fusion avoids that path by representing the shared expert as another expert slot in the same DeepEP MoE layout. In DeepSeek V3/R1, the router still selects the original routed top-k experts, and the TopK output gets one additional column for the shared expert. In the DeepEP physical expert ID layout, each rank reserves one extra shared-expert slot next to its routed experts. This lets routed experts and the shared expert share the same DeepEP dispatch, grouped-GEMM, and combine flow.
This is why the Waterfill feature was split into two pieces:
- #20089 fuses the shared expert into the DeepEP MoE path with a fixed local assignment.
- #19290 adds Waterfill, which replaces the fixed assignment with load-aware shared-expert dispatch.
The fusion itself is not the final load balancing algorithm. It is the required mechanism that makes shared-expert dispatch visible to DeepEP and therefore controllable by Waterfill.
LPLB: LP-Based Load Balancing for Redundant Expert Replicas
The Problem LPLB Solves
EPLB places redundant replicas of hot logical experts and then, by default, splits each hot expert's tokens evenly across its physical copies. Even splitting is optimal only when the offline distribution used to build the placement matches the live traffic. In practice it often does not: a single batch concentrates on different experts than the calibration set, the served dataset drifts away from the recording dataset, and the rebalance period is long enough that placement is effectively static for many batches. When that happens, evenly dividing a hot expert's load still leaves the ranks that own its copies unevenly loaded relative to the rest of the EP group, and the whole group waits on the busiest rank.
LPLB closes this gap at dispatch time. For each MoE layer, on each batch, it looks at the actual per-expert token counts and decides how to split each replicated expert's tokens across its physical copies so that the maximum per-rank load is minimized. It does not move weights and it does not change the router's logical top-k choices — it only chooses, among the valid physical replicas of a logical expert, how much traffic each replica receives. The result is an optimal min–max assignment for the batch in front of it, rather than the static even split EPLB bakes in offline.
The LP Formulation
LPLB casts this as a small linear program solved per layer. The intuition maps directly onto the constraints:
- Objective — minimize the peak. Introduce a scalar
Mrepresenting the maximum load over all ranks, and minimize it. DrivingMdown pulls the busiest rank toward the average, which is exactly what shortens the grouped-GEMM tail that EP imbalance creates. - Rank-load constraints. For every rank, (load from its redundant-expert copies) + (load from its single-copy experts) + (slack to the peak) = M. The single-copy load on each rank is fixed input — those experts have no dispatch choice. Each rank gets one such equation; the slack is non-negative, so
Mis forced to be at least every rank's true load. - Redundant-expert conservation. For every replicated logical expert, the loads assigned to its copies must sum to that expert's total observed load: , where is the load placed on copy and is the expert's total observed load. This guarantees LPLB only redistributes existing traffic and never invents or drops tokens.
The decision variables are the per-copy loads of the replicated experts plus the per-rank slacks and M. Single-copy experts are not variables — they contribute only fixed terms — which keeps the LP small: its size scales with the number of redundant experts and the number of ranks, not the full expert count.
The constraint matrix is split into an offline part and an online part. The structural blocks — the copy-to-logical-expert mapping, the per-rank ownership of replicated copies, and the slack/−M columns — depend only on the expert-to-GPU placement, so they are pre-computed once at startup and after every EPLB rebalance. Only the right-hand side changes per batch: the observed redundant-expert loads and the per-rank single-copy loads. A Big-M auxiliary column keeps the system feasible during the solve and is penalized heavily in the objective so the solver drives it to zero.
From Global Counts to a Solved LP
A subtlety of DP-attention is that different EP ranks run different forward modes in the same step — prefill, decode, or idle — so no single rank sees the global token distribution. LPLB handles this with a deliberately simple collective design:
- Each rank counts its local tokens per logical expert.
- All EP ranks participate in one all-reduce of those counts — idle ranks contribute zeros — so every rank ends up with the identical global per-expert distribution.
- Every rank then solves the same LP independently from those identical inputs and obtains the same solution, so no broadcast of the result is needed.
The LP itself is solved on-GPU by a fused interior-point-method (IPM) kernel built on cuSOLVERDx/cuBLASDx, pre-compiled for the layer's matrix shape at startup so the first real request does not pay the JIT cost. The whole per-batch path — build the right-hand side, solve, and extract the per-copy split — collapses into three CUDA kernel launches that write into pre-allocated buffers, keeping launch overhead and host syncs off the critical path.
From LP Solution to Token Dispatch
The LP returns, for each replicated logical expert, how its load should be divided across its physical copies. LPLB normalizes this into a per-expert probability distribution over the valid physical copies (log2phy_prob). At dispatch, each token routed to a replicated logical expert samples a physical copy from that distribution; single-copy experts map to their one physical location as before. This is a drop-in replacement for the existing dynamic policy, which picks a copy uniformly at random — LPLB keeps the same probabilistic, per-token dispatch shape but replaces the uniform draw with the load-optimal distribution computed for the batch.
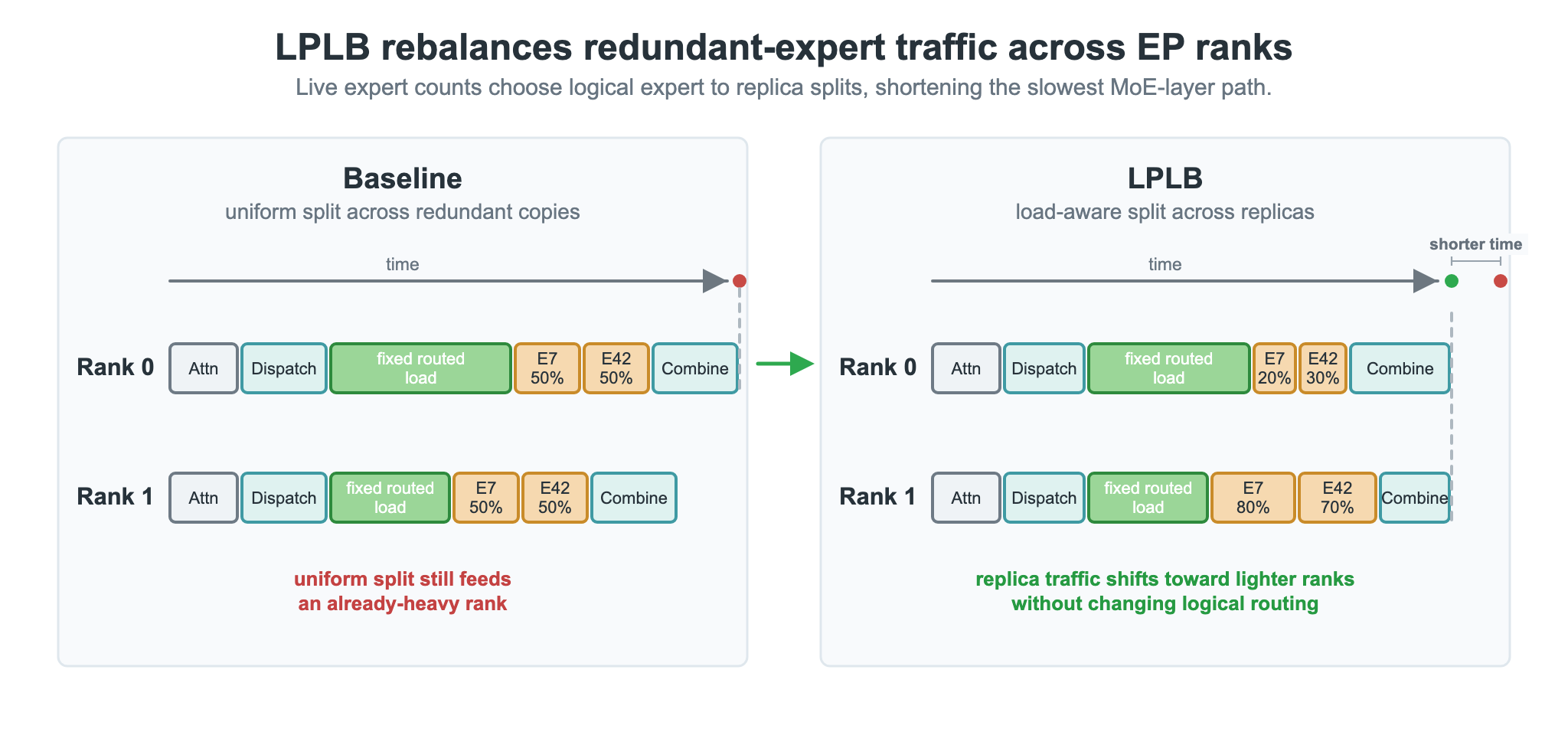
Figure 2. LPLB shifts replicated-expert traffic toward lighter ranks without changing logical expert routing, so the same selected expert can finish on a less-loaded physical replica when redundant copies are available.
How LPLB Differs from Waterfill
Waterfill and LPLB share the end goal — flatten per-rank load under DeepEP — but act on different dispatch choices, with different machinery:
| Waterfill | LPLB | |
|---|---|---|
| Target | The shared (dense) expert, applied to every token | The routed experts that EPLB has replicated |
| Decision | Which rank executes each token's shared-expert slot | How to split each replicated expert's tokens across its physical copies |
| Method | Lightweight valley-filling heuristic over current rank loads | Per-layer min–max linear program solved on-GPU |
| Requires | Shared expert fusion | EPLB redundant replicas to exist |
| Cost | Near-zero overhead | An all-reduce plus an LP solve per layer |
They are complementary rather than competing: Waterfill removes imbalance contributed by the dense shared expert, while LPLB removes imbalance among the sparse routed replicas. Because LPLB only redistributes traffic across valid replicas of the same logical expert and never alters the router's logical top-k, it preserves model semantics for the same reason Waterfill does.
When LPLB Helps Most
LPLB's benefit tracks how much the live batch deviates from the distribution EPLB was calibrated on. When traffic is well-balanced and batches are huge (large-scale, highly diverse serving), there is little residual imbalance left for the LP to remove. When traffic is essentially invariant and narrow (a handful of near-identical questions), static EPLB already captures the distribution and an even split is close to optimal. LPLB delivers the strongest signal in between — medium-scale serving focused on a moderate number of related topics, where each batch is imbalanced in a way the offline placement did not anticipate but is still structured enough that an optimal per-batch split meaningfully lowers the peak rank load.
Evaluation
Waterfill and LPLB on DeepSeek V3/R1
We evaluated Waterfill and LPLB on the same DeepSeek-V3/R1-style serving setup.
The table below corresponds to the direct SGLang integration run
dsv3_ep16_three_dataset_lplb_matrix_20260605_101821, using SGLang commit
a462e0f864103785fd3e64327104103f1356f220.
The benchmark configuration was:
- Model: DeepSeek-V3 FP8, used as the DeepSeek-V3/R1-style serving workload.
- Hardware: two Hopper GPU nodes, 16 GPUs total.
- Parallelism and backend: TP16, DP16, EP16, DP attention, DeepEP normal mode.
- Datasets: MMLU, GPQA, and GSM8K prompt pools.
- Benchmark shape:
batch_size=1000,concurrency=256,request_rate=inf,max_tokens=1.
The table keeps each comparison within the same placement configuration. LPLB is only meaningful when EPLB placement is enabled, because it routes among valid physical replicas of the same logical expert.
| Dataset | Baseline setting | Baseline | Waterfill | Waterfill gain | LPLB | LPLB gain |
|---|---|---|---|---|---|---|
| MMLU | No EPLB | 28,968 tok/s | 29,697 tok/s | +2.52% | - | - |
| MMLU | Static EPLB, red0 | 30,392 tok/s | 31,424 tok/s | +3.40% | 29,938 tok/s | -1.50% |
| MMLU | Static EPLB, red16 | 30,638 tok/s | 31,483 tok/s | +2.76% | 31,104 tok/s | +1.52% |
| MMLU | Static EPLB, red32 | 30,714 tok/s | 31,169 tok/s | +1.48% | 31,547 tok/s | +2.72% |
| GPQA | No EPLB | 23,201 tok/s | 24,283 tok/s | +4.66% | - | - |
| GPQA | Static EPLB, red0 | 26,322 tok/s | 26,970 tok/s | +2.46% | 25,899 tok/s | -1.61% |
| GPQA | Static EPLB, red16 | 26,124 tok/s | 26,683 tok/s | +2.14% | 26,350 tok/s | +0.86% |
| GPQA | Static EPLB, red32 | 25,975 tok/s | 26,655 tok/s | +2.62% | 26,193 tok/s | +0.84% |
| GSM8K | No EPLB | 29,649 tok/s | 30,892 tok/s | +4.19% | - | - |
| GSM8K | Static EPLB, red0 | 33,058 tok/s | 34,529 tok/s | +4.45% | 32,744 tok/s | -0.95% |
| GSM8K | Static EPLB, red16 | 34,026 tok/s | 35,226 tok/s | +3.53% | 35,474 tok/s | +4.26% |
| GSM8K | Static EPLB, red32 | 33,988 tok/s | 35,070 tok/s | +3.19% | 36,482 tok/s | +7.34% |
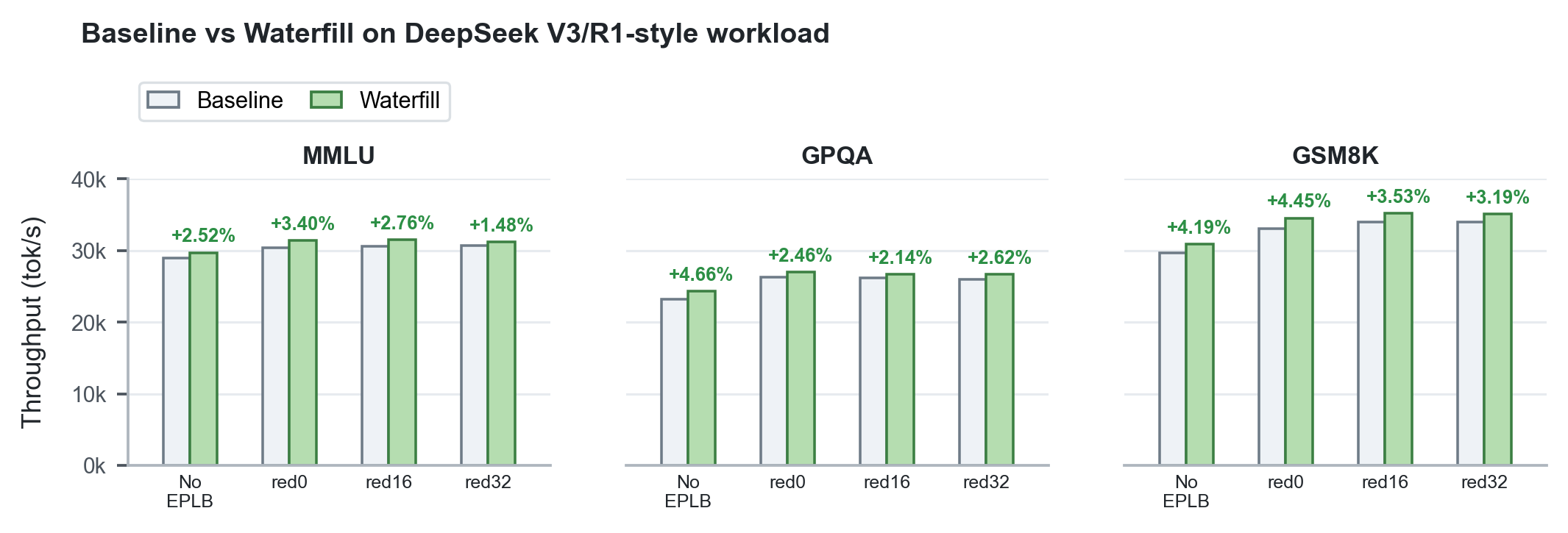
Figure 3. Across MMLU, GPQA, and GSM8K, Waterfill consistently raises total throughput over the matched baseline by shifting shared-expert work toward less-loaded EP ranks.
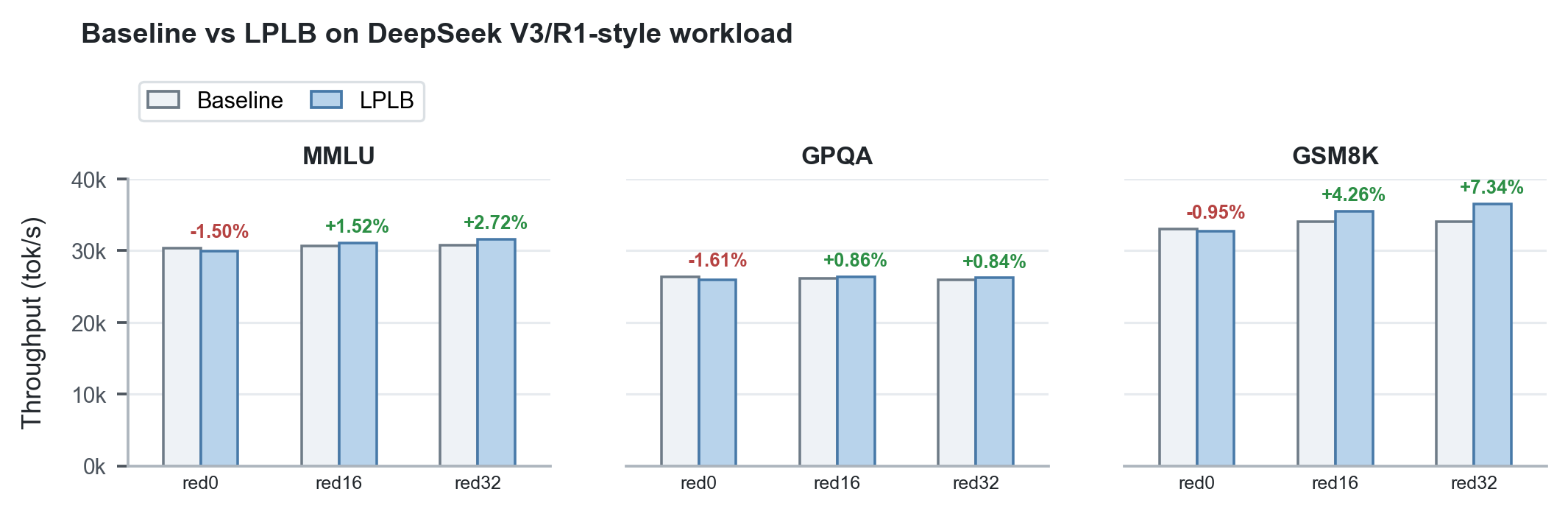
Figure 4. LPLB improves throughput when redundant expert replicas exist (red16/red32) because the LP has physical copies to choose among. With red0, there are no redundant replicas to rebalance, so the algorithm cannot improve dispatch and its all-reduce/solve path appears only as overhead.
These results indicate that Waterfill improves throughput while preserving model quality, because it only changes physical shared-expert placement and does not change the logical expert computation. LPLB is strongest when redundant expert replicas provide useful dispatch choices, as shown by the red16 and red32 rows. In contrast, when no redundant experts are provided, LPLB has no room to balance the load and thus shows only the algorithm overhead.
Waterfill on DeepSeek V4
DeepSeek V4 can use a HashTopK routing path, where Waterfill must append
and remap the shared-expert slot in the HashTopK output path as well.
#25391 extends Waterfill to
that path. The shared-expert balancing idea itself is not specific to
HashTopK; it also applies to non-HashTopK routing paths.
DeepSeek V4 Flash FP8 on two Hopper GPU nodes showed consistent throughput improvement on the MMLU-style serving workload. This V4 Flash run uses the 14,042-prompt MMLU pool, batch=512, concurrency=128, max_tokens=1, 2 warmup rounds, and 4 measured rounds. The table reports trimmed mean total throughput. Because this V4 Flash run used a smaller batch/concurrency shape, these numbers should be read as V4-specific validation rather than a direct throughput comparison against the DeepSeek-V3/R1-style matrix above.
| Configuration | Baseline | Waterfill | Gain |
|---|---|---|---|
| No EPLB | 45,951 tok/s | 47,876 tok/s | +4.19% |
| Static EPLB, red0 | 49,253 tok/s | 51,677 tok/s | +4.92% |
| Static EPLB, red16 | 50,006 tok/s | 51,655 tok/s | +3.30% |
| Static EPLB, red32 | 50,167 tok/s | 51,813 tok/s | +3.28% |
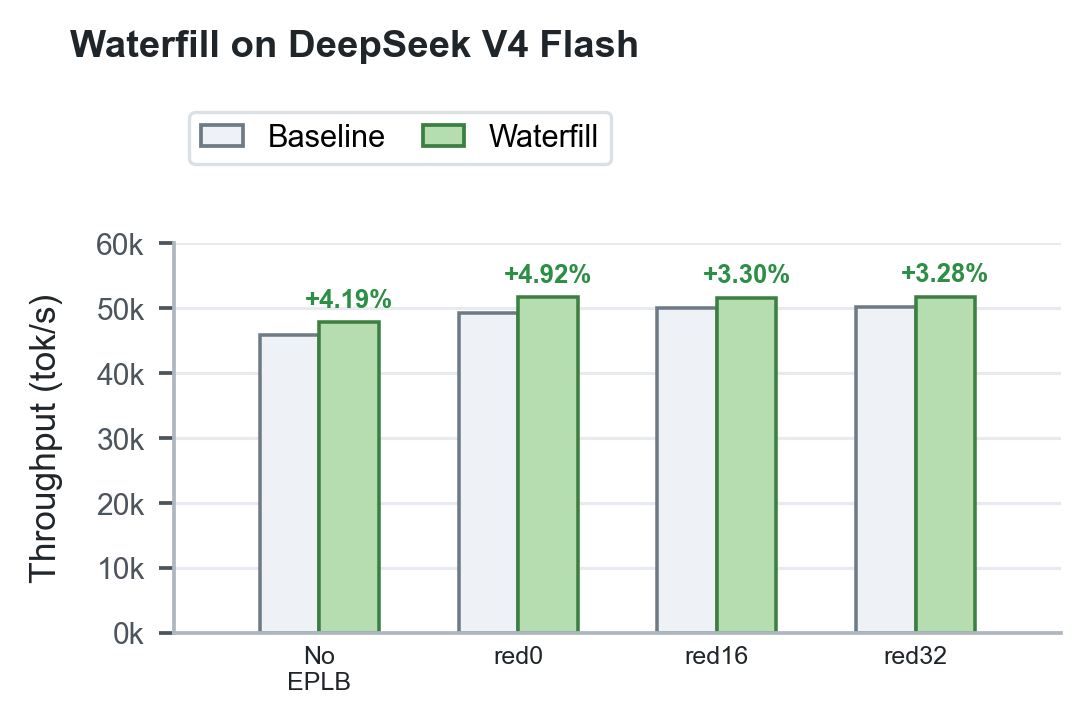
Figure 5. Waterfill is also effective on DeepSeek V4 Flash, improving throughput across no-EPLB and static-EPLB settings with gains from +3.28% to +4.92%.
These results validate that Waterfill remains directionally positive on DeepSeek V4 Flash in addition to the DeepSeek-V3/R1-style workloads above.
Accuracy Validation
Waterfill preserves model semantics because it does not alter the router's logical top-k decisions. The routed experts selected by the model remain the same, and the shared expert remains the same shared expert. Waterfill only changes which physical EP rank executes the shared expert slot.
LPLB preserves model semantics for the same structural reason. It never alters the router's logical top-k; it only chooses which physical replica of a selected logical expert executes each token. Because all replicas of a logical expert hold identical weights, the result a token receives is independent of which replica processes it. This is the same accuracy guarantee EPLB and the dynamic policy already rely on.
How to Use
Enable Waterfill
Waterfill is enabled through the DeepEP MoE path. A representative launch command is:
python3 -m sglang.launch_server \
--model-path /path/to/DeepSeek-V3 \
--tp 16 \
--dp-size 16 \
--nnodes 2 \
--node-rank ${NODE_RANK} \
--dist-init-addr ${HEAD_NODE_IP}:${PORT} \
--host 0.0.0.0 \
--port 30000 \
--trust-remote-code \
--moe-a2a-backend deepep \
--deepep-mode normal \
--enable-dp-attention \
--enable-deepep-waterfill \
--init-expert-location /path/to/expert_distribution.pt
The important flags are:
--moe-a2a-backend deepep: use DeepEP for MoE all-to-all dispatch.--enable-deepep-waterfill: enable the shared expert fusion and Waterfill path.--init-expert-location: optionally initialize expert placement and rank-load metadata from collected expert distribution statistics.
DeepSeek V4 support uses the HashTopK path added in
#25391.
Enable LPLB
LPLB is selected through the EP dispatch algorithm on the DeepEP MoE path. Because LPLB balances tokens across redundant replicas, it requires an EPLB placement that actually contains redundant experts. A representative two-node launch command is:
python3 -m sglang.launch_server \
--model-path /path/to/DeepSeek-R1 \
--tp 16 \
--dp-size 16 \
--ep-size 16 \
--nnodes 2 \
--node-rank ${NODE_RANK} \
--dist-init-addr ${HEAD_NODE_IP}:${PORT} \
--host 0.0.0.0 \
--port 30000 \
--trust-remote-code \
--moe-a2a-backend deepep \
--deepep-mode normal \
--enable-dp-attention \
--ep-num-redundant-experts 16 \
--ep-dispatch-algorithm lp \
--init-expert-location /path/to/expert_stats.pt
The important flags are:
--ep-dispatch-algorithm lp: select the LPLB linear-programming dispatcher in place of the defaultstaticor the uniform-randomdynamicpolicy.--ep-num-redundant-experts: create redundant physical replicas for hot logical experts. LPLB has nothing to balance without them — this is why thered0rows above show no LPLB gain.--init-expert-location: load the static EPLB placement (the physical-to-logical map, including the redundant slots) collected from an expert-distribution recording run. The replica count here must be consistent with--ep-num-redundant-experts.
Acknowledgment
This work builds on the SGLang DeepEP and MoE serving stack and was developed through community collaboration in the SGLang project.
We thank the SGLang maintainers and reviewers for discussions, reviews, and integration support across the related PRs:
- #20089: Fuse shared expert into MoE dispatch under EP
- #19290: Add Waterfill load balancing for shared expert dispatch
- #25391: Support DeepSeek V4 DeepEP Waterfill
- #24515: LPLB: linear-programming load balancer for MoE expert parallelism
We gratefully acknowledge the people who contributed to this work:
- NVIDIA team: Xuting Zhou, Fei Liang, and Aichen Feng
- SGLang team: Cheng Wan
We also thank DeepSeek for open-sourcing their LPLB work at deepseek-ai/LPLB, whose linear-programming formulation for balancing tokens across redundant expert replicas inspired the SGLang LPLB integration described here.