Deploying DeepSeek on GB300 NVL72: Big Wins in Long-Context Inference
TL;DR
As the latest addition to the Blackwell family, the GB300 NVL72 is the most powerful platform for long-context LLM inference. In this blog post, we share our latest progress on optimizing DeepSeek R1-NVFP4 for 128K/8K ISL/OSL (Input Sequence Length/Output Sequence Length) long-context serving using prefill–decode disaggregation (PD), chunked pipeline parallelism (PP) for prefill, wide expert parallelism (Wide-EP) for decode, multi-token prediction (MTP), overlap scheduling, and faster attention kernels driven by 2x Special Function Unit (SFU) throughput increase in key instructions used in attention softmax.
Under long-context workload, SGLang achieves up to 226 TPS/GPU on GB300 NVL72 (1.53X over GB200), under nearly identical GPU throughput, MTP can further achieve an 1.87X increase in per-user throughput (TPS/User).
Furthermore, when compared with matched GB200 NVL72 settings under the same latency conditions, GB300 consistently delivers 1.4X–1.6X TPS/GPU across representative scenarios.
Reproduction instructions can be found here issue:18703.
Highlights
- Long-context (128K/8K) peak throughput: SGLang achieves 226.2 TPS/GPU on GB300 NVL72, with 1.53X advantage over GB200. Under the same throughput, MTP drives 1.87X TPS/User.
- GB300 vs GB200 under matched latency condition: GB300 delivers 1.38X-1.58X TPS/GPU vs GB200 under matched workloads.
- EP decode scaling: GB300's 1.5X larger HBM (288 vs 192 GB) enables 1.6X higher effective decode batch size (40 vs 24 req/GPU), scaling to 288 concurrent requests at DEP8 with minimal retraction.
- PP prefill & optimized Attention kernel: 8.6s TTFT for 128K prefill with dynamic chunking (1.07X–1.23X lower than GB200), powered by a 1.35X faster FMHA kernel via 2x SFU throughput increase in key instructions used in attention softmax.
Methods
This section describes the main techniques that enable GB300’s long-context gains.
1. Deployment & Integration with NVIDIA Dynamo
In this blog, the deployment of DeepSeek-R1 on GB300 NVL72 is orchestrated using NVIDIA Dynamo, a high-performance control plane for cluster-scale prefill–decode (PD) disaggregated inference. Dynamo handles the complexities of coordinating heterogeneous prefill and decode worker pools, providing KV-cache-aware routing, worker coordination, lifecycle management, and an optimized pre- and post-processing stack to sustain ultra-high throughput at scale.
- Low-Overhead Orchestration: Dynamo’s primary performance advantage lies in its lightweight kv-cache aware request steering and efficient metadata management. In long-context scenarios where PD coordination is frequent, Dynamo ensures that the scheduling layer introduces near-zero latency, allowing SGLang’s optimized kernels to saturate the GB300's HBM3e bandwidth without being bottlenecked by orchestration logic.
- Production-Ready Scaling: Dynamo provides robust coordination for multi-node PD deployments, including dynamic worker discovery, health tracking, and lifecycle management across heterogeneous prefill and decode pools, so the deployment remains stable as instances scale up, roll, or restart.
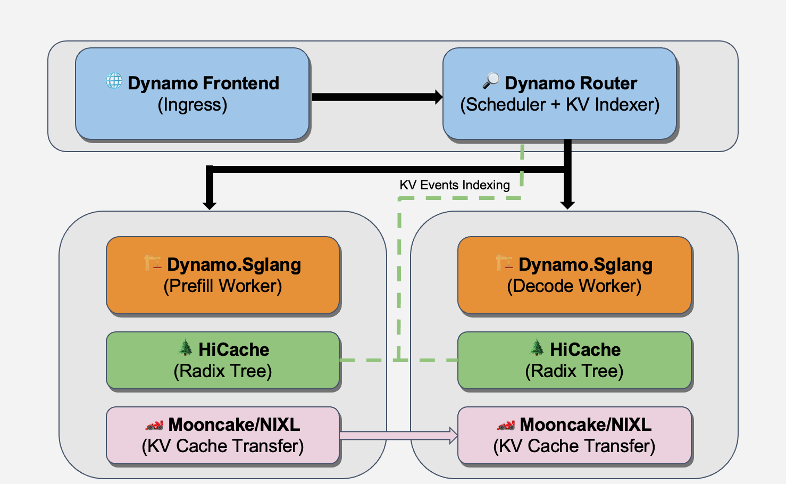
For those wanting to deploy these recipes in production, the Dynamo Kubernetes stack offers GB200/GB300 support with inference-aware autoscaling and cluster topology-aware scheduling for disaggregated deployments.
2. Prefill Path: PP Prefill, Long-Context TTFT, and Faster Kernels
For long-context inference (e.g., 128K tokens), TTFT is a primary constraint especially when little or no prefix matched, and the improvement of TTFT is critical. We address this with Chunked Pipeline Parallelism (PP) for the prefill path combined with Dynamic Chunking, which distributes prompt computation and improves overlap between pipeline stages.
Building on our optimizations from the GB200 series, we have fully enabled FP8 Attention and introduced native FP8 KV-cache support for both prefill and decode. Key advantages:
- Reduced Memory Traffic: Minimizes memory bandwidth bottlenecks compared to BF16, improving throughput and stability.
- Doubled KV Capacity: Doubles the KV-cache capacity within a fixed memory footprint, enabling larger batch sizes or extended sequence lengths.
We also utilize GB300-specific hardware accelerated Softmax for the Attention kernel. Blackwell Ultra GPUs feature an upgraded Special Function Unit (SFU), providing 2x accelerated throughput for key softmax operations, which can be critical for the attention layer. For attention-heavy workloads like long-context prefill, this directly reduces computation bottlenecks.
Our benchmarks show that this upgrade delivers a 1.35X speedup for the FMHA kernel compared to GB200, lowering overall TTFT.
3. Decode path: The Memory Bottleneck in Long-Context Inference
Long-context decode quickly becomes KV-dominated and memory-bound: each new token repeatedly reads the full KV history, so both KV capacity (how many sequences can stay resident) and HBM bandwidth become the primary bottlenecks.
SGLang employs a specialized runtime stack and architectural strategy:
- Wide-EP Scaling: EP (Expert Parallelism) along with DP attention distributes MoE weights and KV cache across more GPUs (up to 32 in this work), reducing memory pressure per GPU and allowing larger decode batch sizes without triggering "retraction" (recomputation).
- CuTe DSL nvfp4 Kernels: Tailored for high-performance nvfp4 MoE operations during decoding.
- DeepEP: An optimized collection of dispatch and combine kernels for efficient all-to-all communication.
GB300 (Blackwell Ultra) features 288 GB of HBM3e per GPU — 1.5X the capacity of GB200's 192 GB. To quantify how GB300’s 288 GB HBM3e translates into effective KV capacity, we evaluate the max decode concurrency with DEP16 as an example. We fix mem_fraction_static = 0.75 on both platforms for fair comparison, though GB300's larger absolute memory allows for a higher setting in practice. We compute max decode batch size from the per-token KV footprint (35,136 Bytes per token) and the 128K+8K workload (~136K cached tokens per request).
In SGLang, mem_fraction_static defines the fraction of GPU memory allocated to model weights and KV cache, with the remainder reserved for activations and runtime buffers.
The computation of KV footprint: (kv_lora_rank + qk_rope_head_dim) × num_layers × num_kv_head * fp8_size = (512 + 64) × 61 × 1 × 1 = 35,136 Bytes per token
| Item | Assumption / Metric | GB300 (@ mfs=0.75) | GB200 (@ mfs=0.75) |
|---|---|---|---|
| HBM per GPU | Total HBM3e capacity | 288 GB | 192 GB |
| Static budget | HBM × mem_fraction_static | ≈ 216 GB | ≈ 144 GB |
| Model weights per GPU | FP4-quantized DeepSeek-R1, EP16/TP16 | ≈ 40 GB | ≈ 40 GB |
| KV pool budget | Static budget – Model weights | ≈ 176 GB | ≈ 104 GB |
| Workload | cached tokens per request | 136K (128K+8K) | 136K (128K+8K) |
| KV footprint | cell_size_per_token | 35,136 B | 35,136 B |
| KV per req per GPU | 136K × cell_size | ≈ 4.45 GiB | ≈ 4.45 GiB |
| Theoretical cap | KV pool / KV per req | ≈ 40 req/GPU | ≈ 24 req/GPU |
| Practical target | ~85% of cap to reduce retraction | ≈ 36 req/GPU | ≈ 20 req/GPU |
| EP16 mapping | req/GPU × 16 GPUs | ≈ 576 concurrent reqs | ≈ 320 concurrent reqs |
As the table shows, GB300's larger HBM translates almost directly into higher decode concurrency — with theoretical caps at 40 vs 24 req/GPU. In practice, we operate at ~85% of the cap to avoid requests fully occupying the KV cache and triggering request retraction, yielding a maximum of 36 req/GPU on GB300 versus 20 on GB200 (i.e., 576 vs 320 concurrent requests at DEP16).
4. MTP Powered by the Overlap Scheduler
Since v0.4, overlap scheduler has been serving as the default batch scheduling strategy for SGLang, with its capacity to reach zero CPU overhead through overlapping CPU scheduling with GPU computation. Meanwhile, Multi-token Prediction (MTP) is one of the most popular speculative decoding methods, widely adopted by mainstream models including DeepSeek R1. More details of MTP implementation in SGLang can be found in this blog.
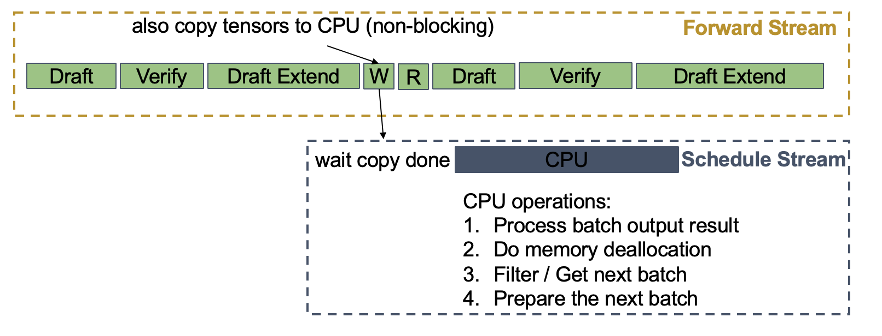
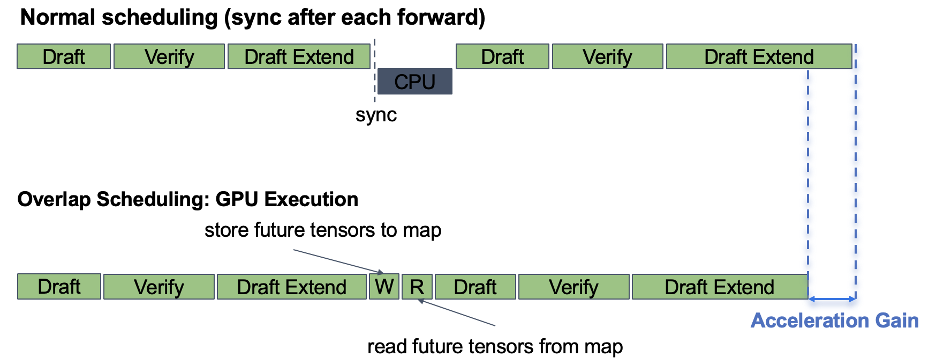
As an effort to combine MTP and overlap scheduler seamlessly, SGLang proposes Spec-V2, which mitigates the synchronization between MTP batches with finely designed message passing and overlapping strategy.
To be specific, Spec-V2 adopts a two-stream design: a forward stream for all the GPU computation, and a schedule stream (here we use term “stream” to emphasize asynchronicity) for CPU operations including result processing, memory deallocation, preparation for the next batch and so on.
To avoid synchronization barriers caused by transferring metadata tensors from device to host, Spec-V2 creates a future tensor map, where the schedule stream first creates the reference of metadata tensors, and only reads them until the last batch materializes them. In this way, the CPU operations can be overlapped with the target verify or draft extend process of the last MTP batch.
Furthermore, we enhanced the support of MTP with overlap scheduler in following parts:
- Compatibility with PD Disaggregation and WideEP, unlocking performance under higher concurrencies.
- Capturing cuda graphs for all stages (draft decode, target verify, draft extend) of MTP forward process, further reducing CPU overhead.
- FP8 quantization of MoE weights in the MTP layer, which works with DeepGemm and DeepEP more smoothly.
Experiments
1. Max Throughput Analysis
To characterize the max throughput of DeepSeek-R1, we measure the maximum achievable TPS under a long-context workload (ISL = 128K, OSL = 8K).
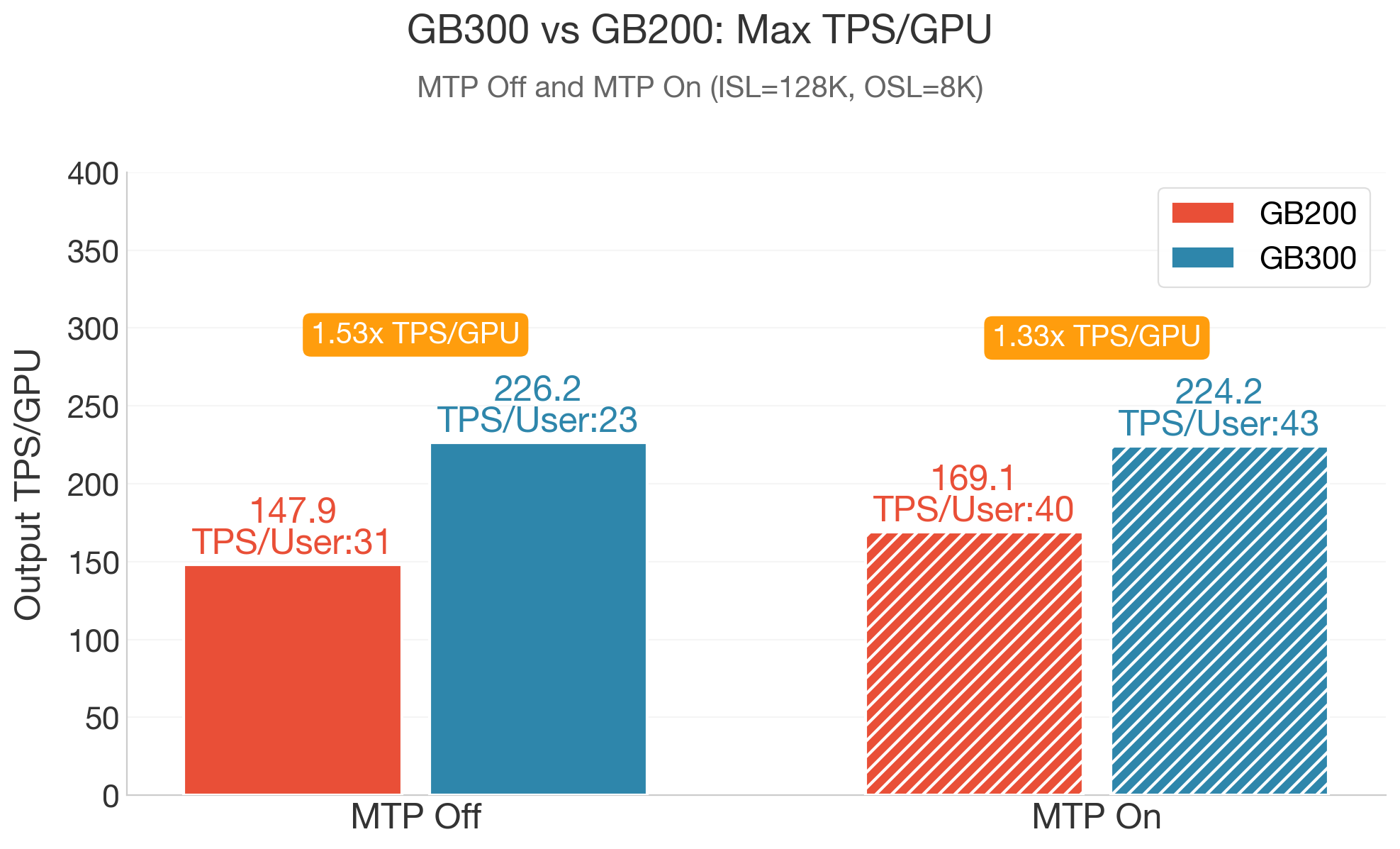
Without MTP, GB300 reaches 226.2 TPS/GPU — 1.53X over GB200 (147.9 TPS/GPU). With long context, the peak throughput is primarily constrained by the decode-side KV cache capacity and memory bandwidth rather than the compute capability; GB300's larger HBM capacity enables higher decode batch size, allowing more requests to remain active without triggering retraction.
With MTP enabled, GB300 sustains 224.2 TPS/GPU versus 169.1 on GB200 (1.33X). Notably, MTP's primary benefit lies in per-user throughput: GB300's TPS/User nearly doubles from 23 to 43 (+87%) while maintaining peak-level TPS/GPU, meaning each user receives significantly faster responses without sacrificing system-wide throughput.
2. Peak Capacity vs. Latency Constraints
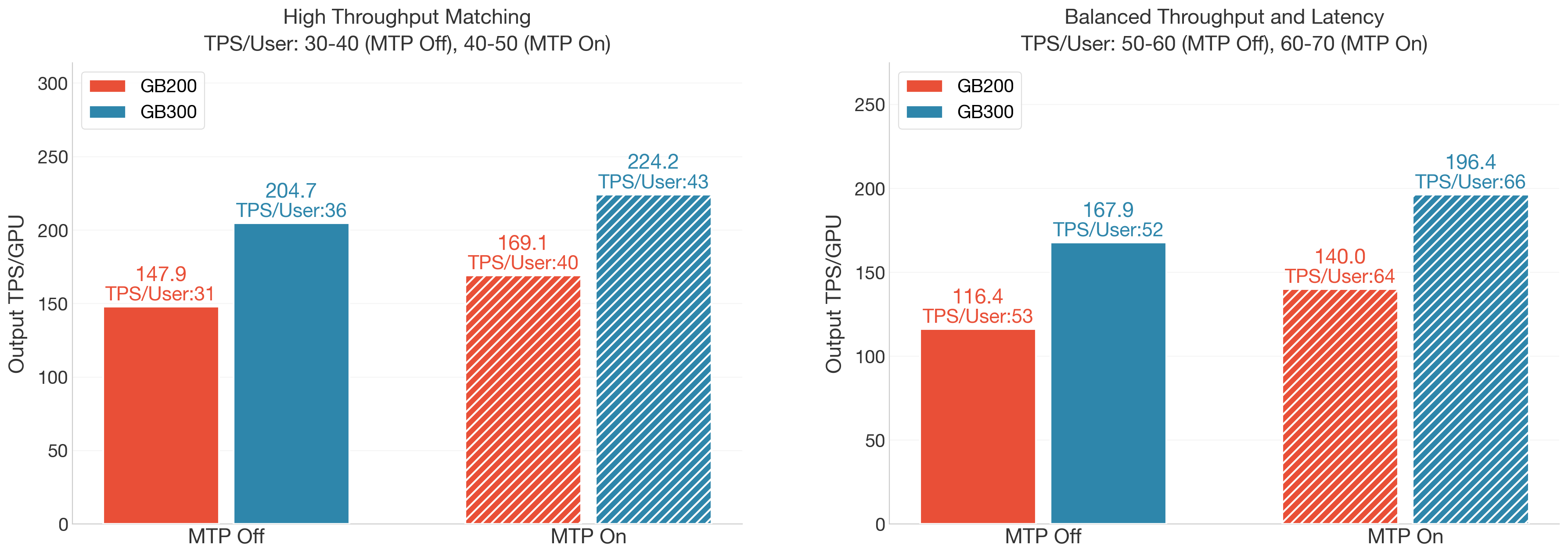
To compare GB300 and GB200 under realistic inference usage, we evaluate performance across two representative scenarios:
- High-throughput-oriented scenario (TPS/User = 30–40 for Non-MTP, 40–50 for MTP), where the system is tuned to maximize aggregate throughput and latency constraints are relaxed.
- Latency–throughput balanced scenario (TPS/User = 50–60 for Non-MTP, 60–70 for MTP), which reflects higher per-user throughput and stricter responsiveness requirements.
In the high-throughput scenario, GB300 achieves 204.7 TPS/GPU versus 147.9 on GB200 (+38.4%) without MTP. With MTP, the speedup is higher with 224.2 vs. 169.1 TPS/GPU (+44.9%).
In the latency–throughput balanced scenario, GB300 maintains 1.58X without MTP (167.9 vs. 106.5 TPS/GPU) and 1.40X gain with MTP (196.4 vs. 140.0 TPS/GPU).
Overall, GB300 consistently outperforms GB200 by 1.4X–1.5X, with the largest relative gains under latency-sensitive conditions where GB300 shows stronger resilience to throughput degradation at higher per-user throughput.
3. Prefill Latency: Chunking Strategies and TTFT Optimizations
To evaluate the impact of chunking strategies and hardware on prefill latency, we benchmark Mean TTFT under a long-context workload (ISL = 128K, OSL = 8K) using a 1P/1D disaggregated setup with 8 GPUs. We compare three chunking dimensions: no chunking (concurrency = 1), static chunking, and dynamic chunking, across initial chunk sizes of 16K, 32K, and 64K.
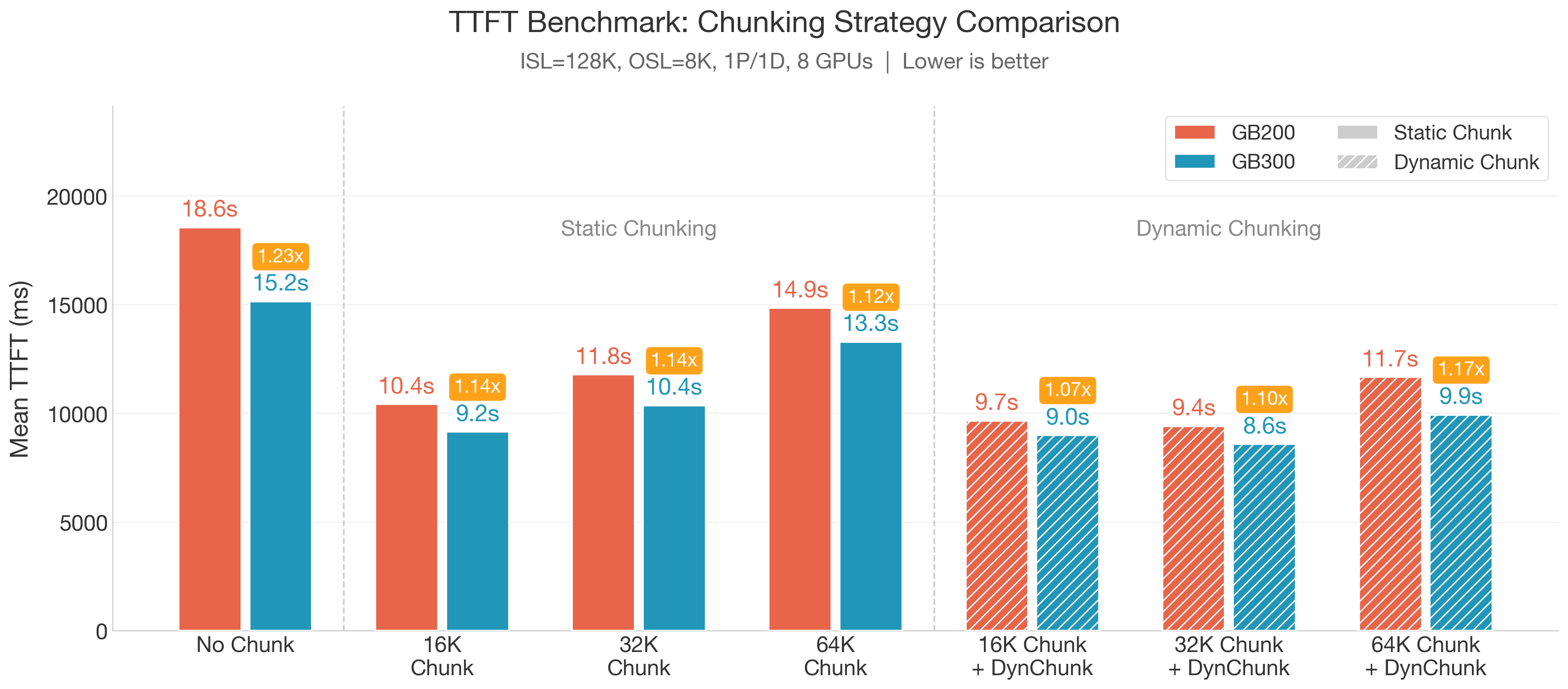
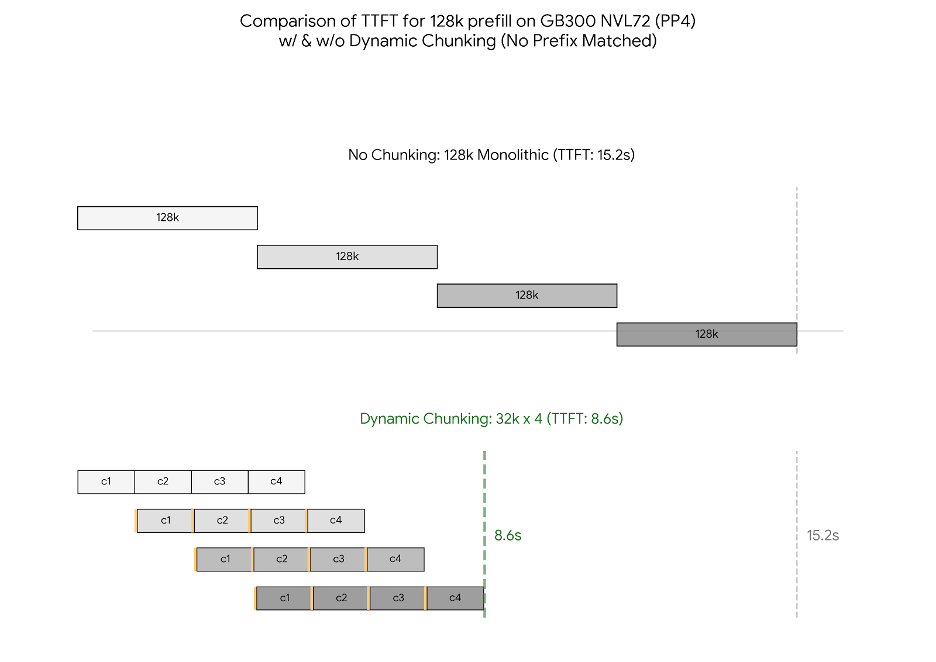
GB300 consistently outperforms GB200 in prefill TTFT. Across all chunking configurations, GB300 achieves 1.07X–1.23X lower TTFT than GB200 under the same settings. The largest gap appears in the no-chunk baseline (15.2s vs. 18.6s), primarily driven by GB300's optimized attention kernel (Section 4.4). With chunking enabled, GB300 maintains a steady advantage, reaching a best-case TTFT of 8.6s for 128K prefill with 32K dynamic chunking.
Chunking and dynamic chunking are helpful for long-context TTFT. Without chunking, TTFT exceeds 15s on both platforms. Enabling chunked prefill with PP overlap reduces TTFT by 30–45%, with smaller chunk sizes (16K, 32K) consistently outperforming 64K due to better pipeline utilization. Dynamic chunking provides a further 8–17% reduction on top of static chunking at every chunk size tested, as it eliminates pipeline bubbles caused by fixed scheduling — an effect particularly pronounced at larger chunk sizes where static chunking leaves significant idle time. Using an initial chunk size of 32K together with dynamic chunking, we achieve a TTFT of 8.6 s on GB300. More fine-grained tuning of smooth factor may further lower the TTFT.
4. Kernel Comparison
To quantify the architectural advantages of GB300, we benchmarked kernel-level performance in a representative long-context prefill scenario.
Test Configuration:
- Workload: Long-context sequence prefill.
- Parallelism: PP4 (Pipeline Parallelism = 4).
- Concurrency: 8.
- Prefill size: 128k, no chunking
GB300 yields a 1.35X speedup for the FMHA kernel over GB200, driven by the SM103a's 2x throughput increase in softmax
| Platform | FMHA Kernel Implementation | Latency |
|---|---|---|
| GB300 | fmhaSm103aKernel_QkvE4m3OBfloat16HQk192HV128SeparateQkvCausalVarSeqqQ128Kv128PersistentContext | 205ms |
| GB200 | fmhaSm100fKernel_QkvE4m3OBfloat16HQk192HV128SeparateQkvCausalVarSeqqQ128Kv128PersistentContext | 277ms |


5. Accuracy
We evaluated our system on LongBench-v2 to ensure the model's integrity. Our non-mtp setup achieved a score of 57.2%. When MTP was enabled, the score, 56.9% with accept length=2.37@MTP3, aligns perfectly with the 56.7% reported in the DeepSeek-R1-0528 official benchmark.
Future Work
Though all the techniques mentioned above have demonstrated the superiority of GB300, we still have the following optimization items for even better performance:
- Context Parallelism: Compared with chunked pipeline parallelism, context parallelism is also a promising and bubble-free option to lower TTFT.
- Kernel Optimizations: Communication kernels can be optimized with symmetric memory enabled. Small metadata preparation kernels for MTP can also be fused for lower CPU overhead.
- DP Load Balancer: With better DP load balancer, waiting time between different DP ranks can be reduced.
- More Overlap in Wide-EP: The MoE computation and DeepEP communication can be scheduled and organized in a finer way, reaching deeper overlap and higher speedup.
- Spec-aware Scheduling for Long Context & Workload: The number of draft tokens can be decided by current workload dynamically.
Acknowledgement
We would like to express our heartfelt gratitude to the following teams and collaborators:
NVIDIA Team — including members from: Yangmin Li, Hao Lu, Ishan Dhanani, Weiliang Liu, Trevor Morris, Po-Han Huang, Kaixi Hou, Shu Wang, Lee Nau, Alex Yang, Mathew Wicks, Pen Chung Li
SGLang Core Team and Community Contributors: Baizhou Zhang, Jingyi Chen, Liangsheng Yin, Shangming Cai, Rain Jiang, Cheng Wan, Qiaolin Yu, Lianmin Zheng