Squeezing 1TB Model Rollout into a Single H200: INT4 QAT RL End-to-End Practice
💡 TL;DR:
Inspired by the Kimi K2 team, the SGLang RL team successfully landed an INT4 Quantization-Aware Training (QAT) pipeline. By combining fake quantization during training with real quantization at inference (W4A16), we achieved stability and train–infer consistency comparable to BF16 full-precision training. Meanwhile, extreme INT4 compression allows single-node rollout for ~1TB-scale models, eliminating cross-node communication bottlenecks and significantly improving rollout efficiency—an open-source reference that balances high performance and low cost.
Introduction
Recently, the SGLang RL team has made significant progress in RL training stability, efficiency, and application scenarios, including:
- INT4 QAT End-to-End Training: We implemented a complete QAT INT4 closed-loop solution from training to inference and provided a detailed technical recipe, significantly improving rollout efficiency and stability.
- Unified Multi-Turn VLM/LLM Training: We provided an implementation for the VLM multi-turn sampling paradigm blog. Developers only need to write a customized
rolloutfunction to easily start multi-turn RL for VLM, just like training LLM. - Rollout Router Replay: We implemented the Rollout Router Replay mechanism, significantly improving RL stability for MoE models during RL training.
- FP8 End-to-End Training: We successfully implemented end-to-end FP8 training and sampling in RL scenarios, further unlocking hardware performance.
- Speculative Decoding in RL: We successfully practiced speculative sampling in RL scenarios, achieving lossless acceleration for large-scale training.
Building on top of these, we went one step further: on the slime framework, we reproduced and deployed an end-to-end INT4 QAT solution: INT4 Quantization-Aware Training (QAT). This solution is deeply inspired by the Kimi team’s K2-Thinking technical report and its W4A16 QAT (Quantization-Aware Training) practice: W4A16 QAT (Quantization-Aware Training). To pay tribute to pioneers and give back to the community, this article dissects the technical details of building the full pipeline in an open-source ecosystem, aiming to provide a practical reference that balances stability and performance.
Key benefits at a glance:
- Break the VRAM bottleneck: With weight compression and low-bit quantization, ~1TB-scale K2-like models can be shrunk to fit on a single H200 (141GB) GPU, avoiding cross-node communication bottlenecks.
- Train–infer consistency: Training uses QAT to shape weights into an INT4-friendly distribution; inference uses W4A16 (INT4 weights, BF16 activations). Both rely on BF16 Tensor Cores, achieving train–infer consistency comparable to BF16 full precision.
- Single-node efficiency doubling: For very large models, INT4 greatly reduces VRAM and bandwidth pressure, delivering rollout efficiency significantly higher than W8A8 (FP8 weights, FP8 activations).
This project is jointly completed by the SGLang RL team, InfiXAI team, Ant Group Asystem & AQ Infra team, slime team, and RadixArk team. Related features and recipes have been synced to the slime and Miles communities. We welcome everyone to try them out and contribute. We are also further challenging ourselves with MXFP8 and NVFP4. We also gratefully acknowledge Verda Cloud for compute resource sponsorship.
Technical Overview
Overall Pipeline
We implemented a complete INT4 QAT closed loop from training to inference, as illustrated below:
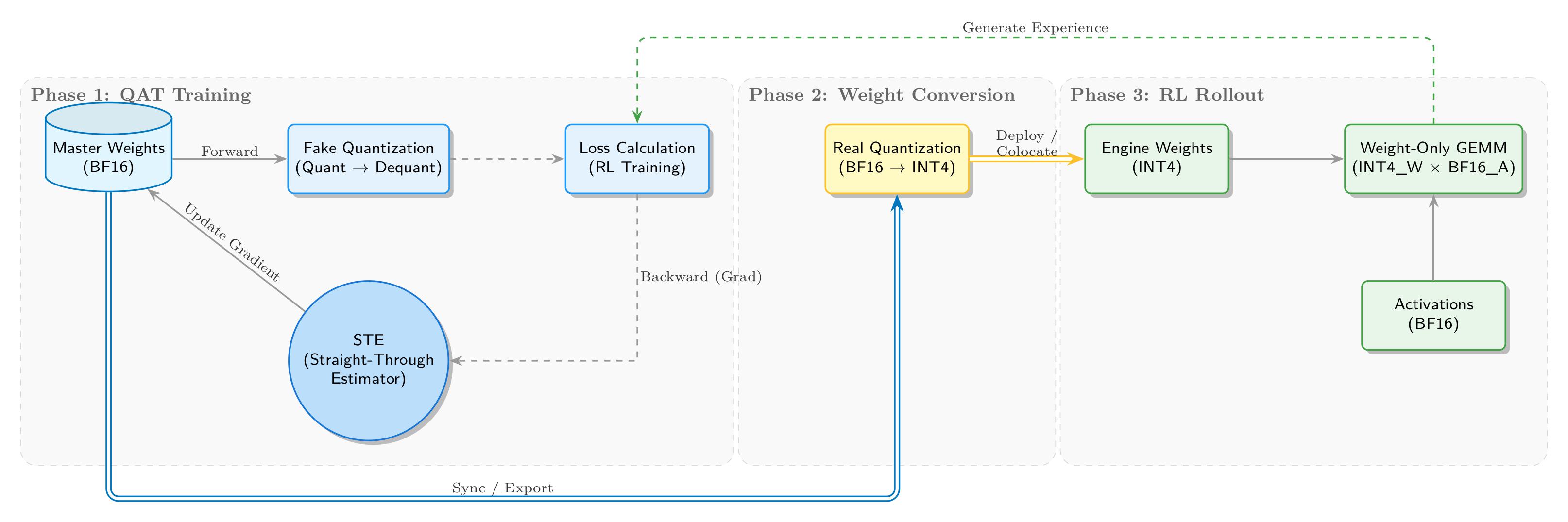
During the QAT training stage, the training side maintains BF16 master weights, while the forward pass introduces quantization noise via fake quantization. “Fake” means we do not truly convert BF16 tensors to low-precision INT4 storage; instead, we keep the floating-point compute path and insert QDQ (Quantize-DeQuantize) operations to emulate low-precision arithmetic. Concretely, high-precision weights are first “discretized” into INT4 and then immediately restored. Although the physical dtype remains floating point, the value precision is effectively reduced. The discrepancy between the original and restored values introduces quantization error, which is mathematically equivalent to injecting noise into the network, forcing the model to adapt to this precision loss via gradient updates.
For the backward pass, we use STE (Straight-Through Estimator) to bypass the non-differentiability of quantization. The core quantization operator is rounding, which is a step function whose derivative is 0 almost everywhere. This would completely block gradient flow and prevent updates to the underlying master weights. STE uses a “straight-through gradient estimator” strategy: during backprop it defines the derivative of rounding as 1 (i.e., treats it as an identity mapping). This is like building a bridge over a cliff, enabling gradients to pass through the rounding layer and update the high-precision floating-point weights, thus closing the QAT training loop.
In the weight conversion stage, we export the converged BF16 weights and perform real quantization, converting them into INT4 formats suitable for inference engines (e.g., Marlin).
In the RL rollout stage, SGLang loads INT4 weights and runs efficient W4A16 inference (INT4 weights × BF16 activations). The generated experience data flows back to the first stage for the next RL training iteration, forming a self-consistent closed loop.
Key Strategy Choices
For quantization format, we follow Kimi-K2-Thinking and choose INT4 (W4A16). Compared to FP4, INT4 has broader support on existing hardware (pre-Blackwell), and the ecosystem already has mature high-performance Marlin kernels. Experiments show that with a 1×32 scale granularity, INT4 provides sufficient dynamic range and stable accuracy, and its performance and tooling are well-optimized. As an industry “good enough” quantization standard, INT4 strikes a rational balance across performance, risk, and maintenance cost. That said, we also plan to explore FP4 RL on NVIDIA Blackwell GPUs in the future.
For training, we use the classic combination of fake quantization + STE. By maintaining BF16 master weights, simulating quantization noise in the forward pass, and passing gradients straight through in the backward pass, we maximize convergence and stability in low-precision training.
Training Side: Retrofitting Fake Quantization into Megatron-LM
Implementing Fake Quantization and STE (Straight-Through Estimator)
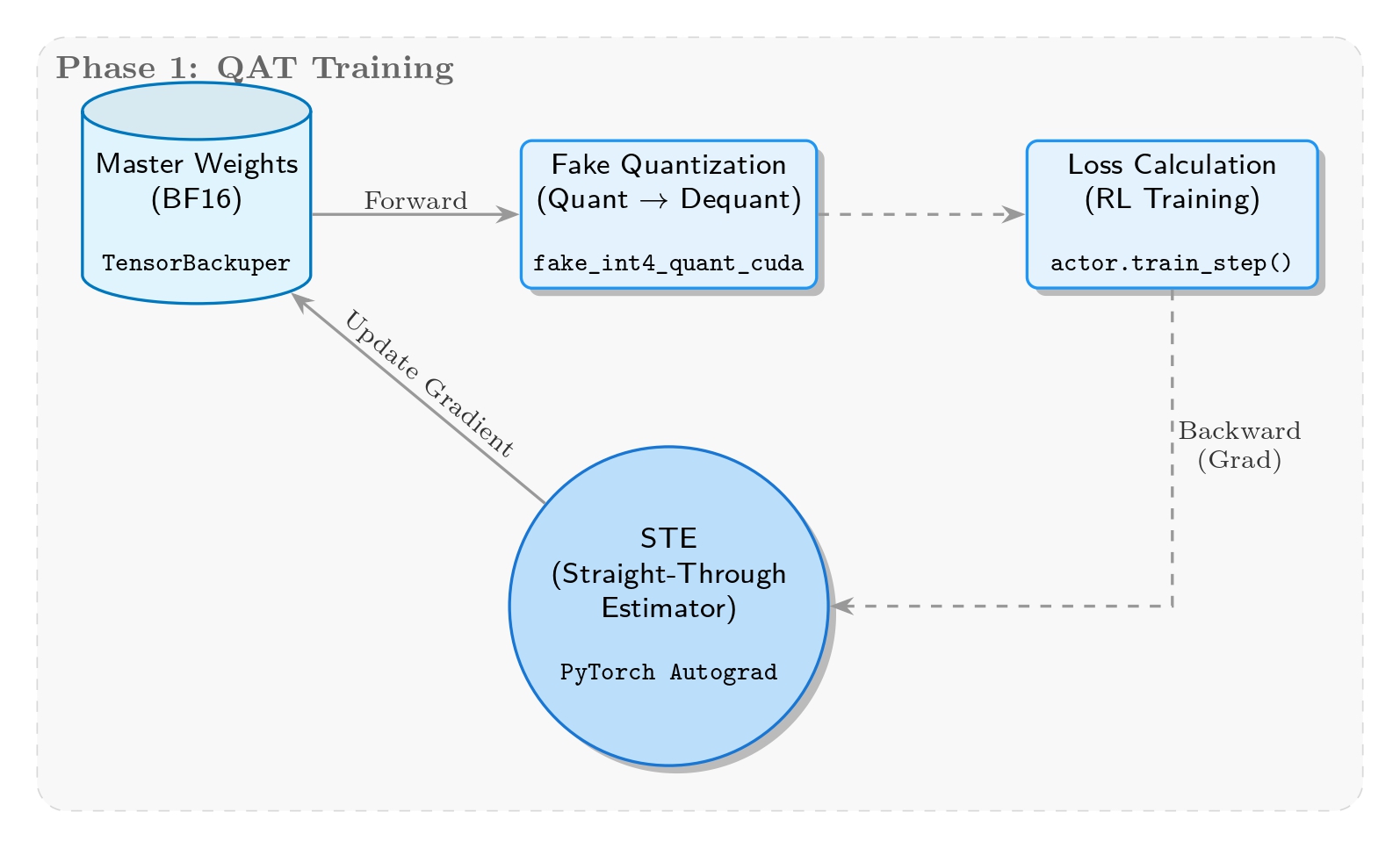
The core goal of this stage is to simulate quantization error on-the-fly during training, forcing the model to “learn” to adapt to low-precision representations. We therefore adopt fake quantization: while weights are stored and updated in BF16, they are temporarily mapped into the INT4 precision range in the forward pass.
Implementation-wise, the core logic lives in the _FakeInt4QuantizationSTE class in megatron/core/extensions/transformer_engine.py. It performs dynamic quantization based on per-group max absolute value, emulating INT4’s [-7, 7] range and clipping, but still computes in BF16 and only injects quantization error. For the crucial backward pass, we introduce STE, ensuring gradients pass through the quantization layer unchanged to update master weights, keeping training continuous.
Fake Quantization Ablations
To validate the necessity of QAT and study the impact of train–infer precision mismatch, we designed ablations for two asymmetric scenarios:
- QAT INT4 training enabled, BF16 rollout
- QAT training disabled, direct INT4 rollout
We measure train–infer inconsistency using the absolute difference in log probabilities (Logprob Abs Diff).
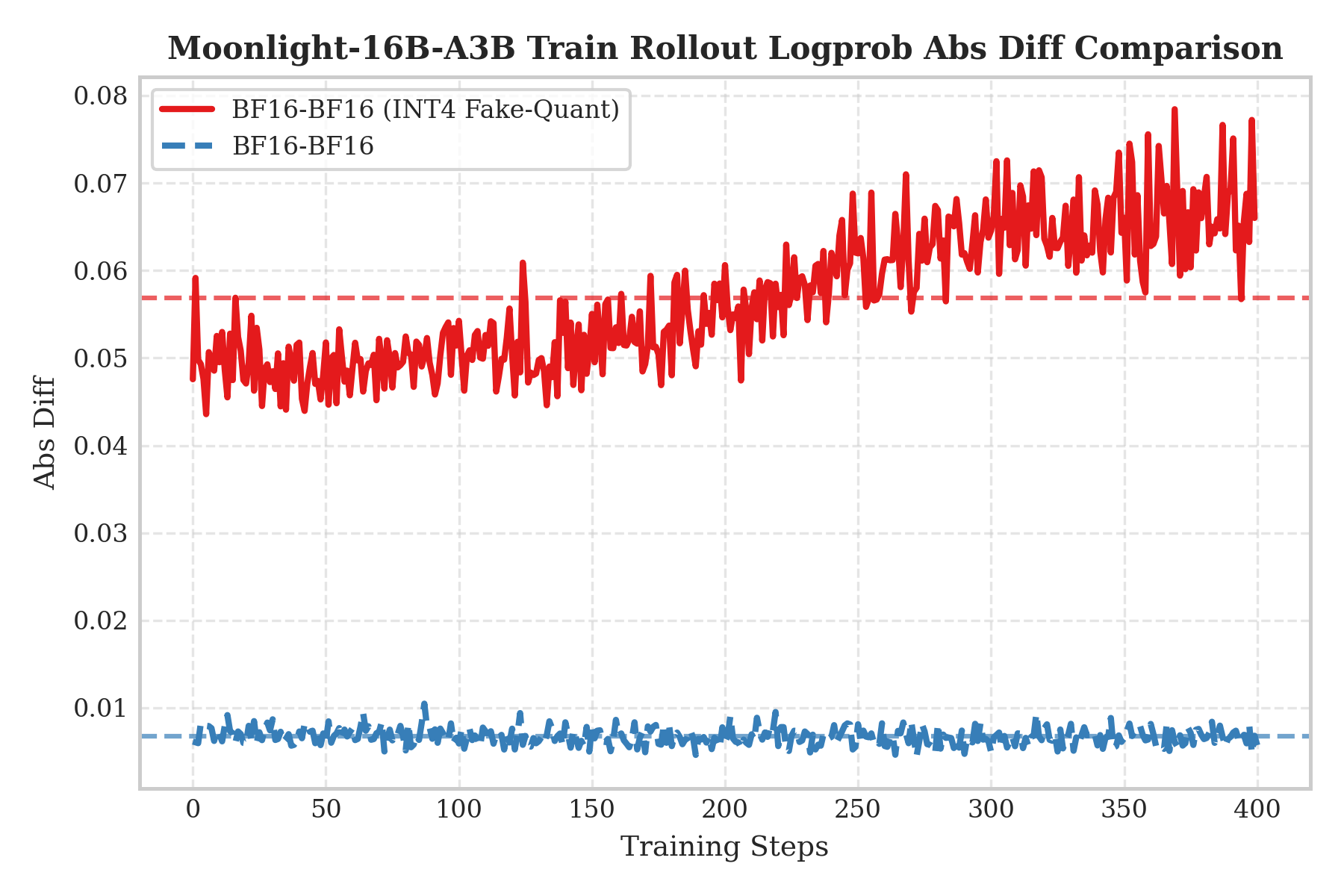
The left plot shows “QAT INT4 training + BF16 rollout” (the red curve). Interestingly, even with high-precision BF16 inference, the error remains significantly higher. This is because QAT has already adapted weights to INT4 quantization noise via “compensation”; if we remove quantization at inference, that compensation becomes a perturbation, causing distribution shift.
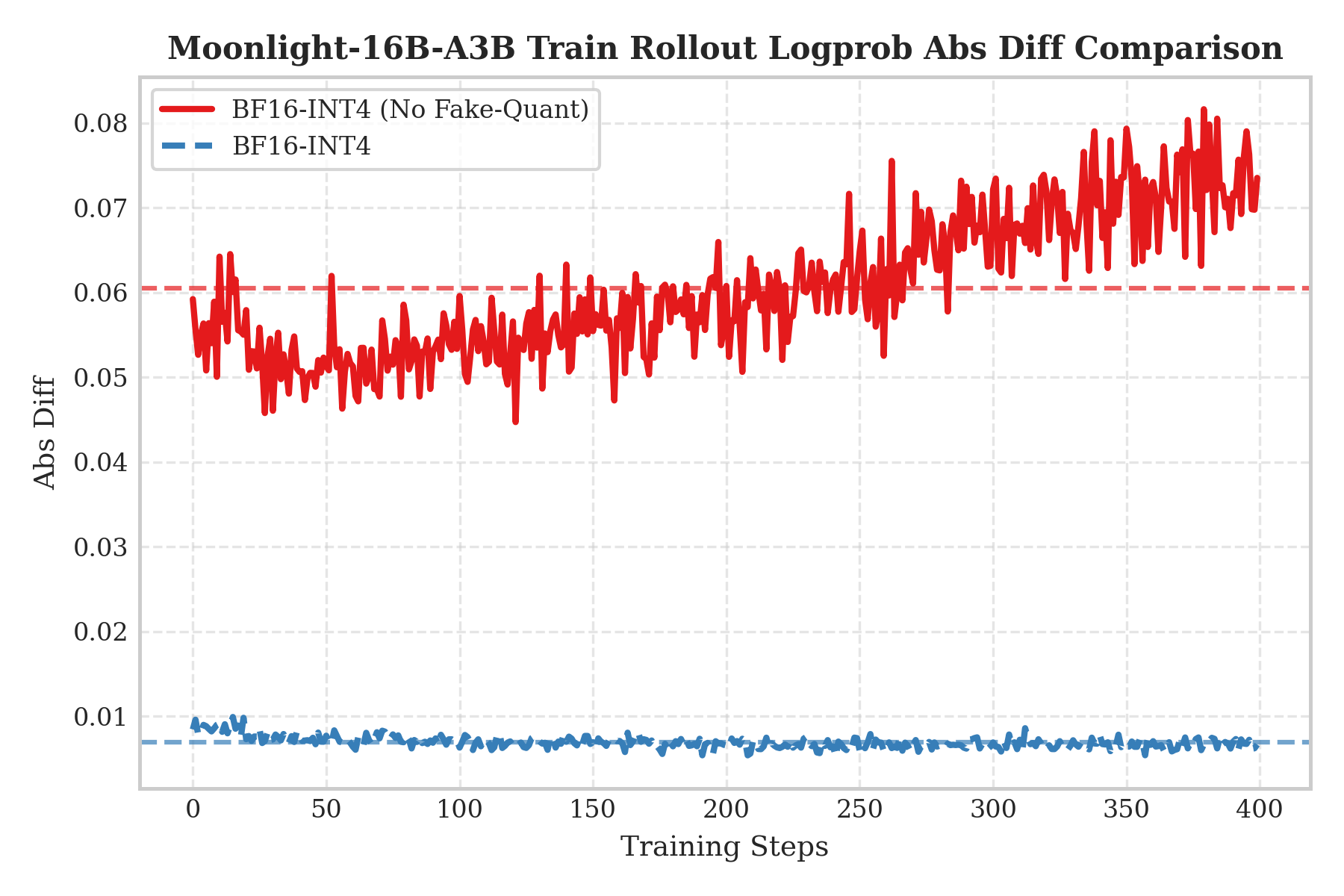
The right plot shows “no QAT training + direct INT4 rollout” (the red curve), corresponding to a conventional post-training quantization (PTQ) setup. Since the model never saw quantization noise during training, compressing weights to INT4 causes severe information loss and shifts feature distributions relative to training, resulting in errors that oscillate and increase with training steps.
Conclusion: These results strongly indicate that training-side fake quantization and inference-side real quantization must be enabled together. Only when the simulated noise during training is strictly aligned with the true quantization during inference can we suppress train–infer mismatch, avoid distribution shift, and keep errors near baseline—thus truly closing the loop for end-to-end low-precision RL training.
Weight Update Stage
Weight Flow and Dynamic Format Adaptation
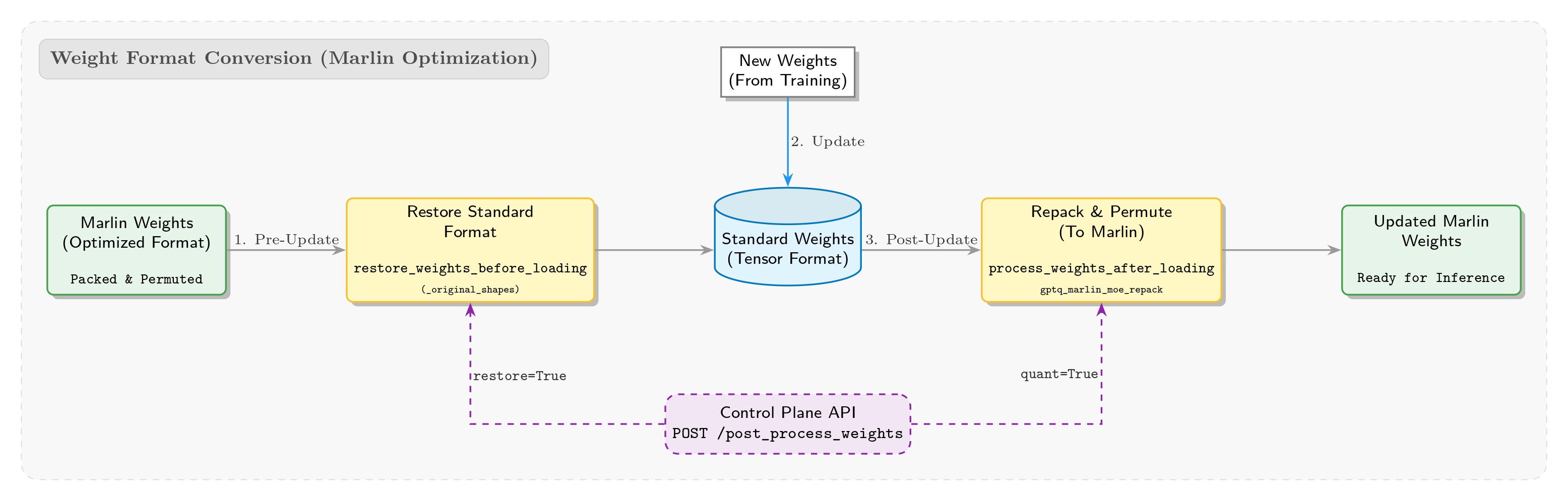
To reuse existing inference-side optimizations in SGLang, we directly adopted its built-in Marlin kernel as the INT4 inference backend. However, in practice we encountered a notable “format gap”: QAT training outputs weights in standard formats (similar to Hugging Face), while SGLang’s Marlin kernel requires weights to be specially packed and permuted so that the kernel can read them efficiently.
Given that RL training requires frequent weight updates, we must solve format compatibility. We therefore designed a reverse restore_weights_before_loading safety mechanism. Using cached _original_shapes metadata, it restores (resizes) the in-memory Marlin weight format back to original shapes before any weight update happens. This prevents runtime errors due to shape mismatches and enables smooth switching between standard weight formats and Marlin formats. We also added a system-level post_process_weights API to allow the control plane to explicitly trigger this process according to the training schedule.
To address post-load format adaptation, we implemented a dynamic weight management mechanism in compressed_tensors_moe.py. After weight loading finishes, the system automatically runs process_weights_after_loading, calling operators like gptq_marlin_moe_repack and marlin_moe_permute_scales to convert standard weights into highly optimized Marlin formats in memory, maximizing memory-access and compute efficiency for inference.
Quantization During Weight Updates

Now comes the core real quantization step. Unlike training-time fake quantization, this step irreversibly compresses precision via int4_block_quantize: with a configured group size, we compute per-group scales and map high-precision floats into the INT4 integer domain [-7, 7].
To maximize VRAM efficiency, we then do bit packing. Since PyTorch lacks a native INT4 dtype, we implement pack_int4_to_int32 using bitwise tricks to tightly pack 8 INT4 values into one INT32 integer (i.e., 8 × 4 bits = 32 bits). Finally, these packed weights together with scales are passed to the inference engine, completing the conversion from “training format” to “inference format”.
Inference Stage
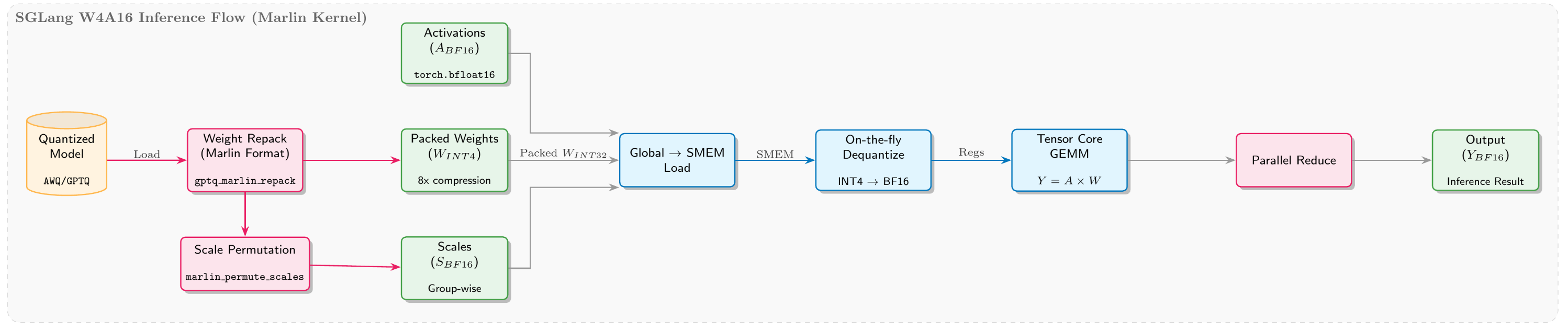
Minimal packing and near-zero-overhead unpacking
During RL rollout, we directly reuse SGLang’s mature W4A16 quantization solution. SGLang stores weights in a compact INT4 format by packing two 4-bit values into one byte, saving 75% memory compared to BF16. At inference time, Triton kernels unpack efficiently using bit operations (>> 4 and & 0xF). Thanks to overlap between compute and IO, this unpacking is almost zero-overhead.
Deep fusion for MoE operators
- Memory optimization: SGLang introduces a dynamic
moe_align_block_sizethat choosesblock_sizebased on current token counts and expert distribution, grouping and aligning tokens for the same expert to improve bandwidth utilization. - Compute fusion: Besides integrating a high-performance Marlin INT4 implementation, SGLang also fuses the gating part into a single high-performance kernel to avoid repeated kernel launches and intermediate reads/writes. This INT4 inference scheme is compatible with mainstream formats such as GPTQ and AWQ, and supports both symmetric and asymmetric modes.
INT4 QAT RL Results
Training Results
- Training side
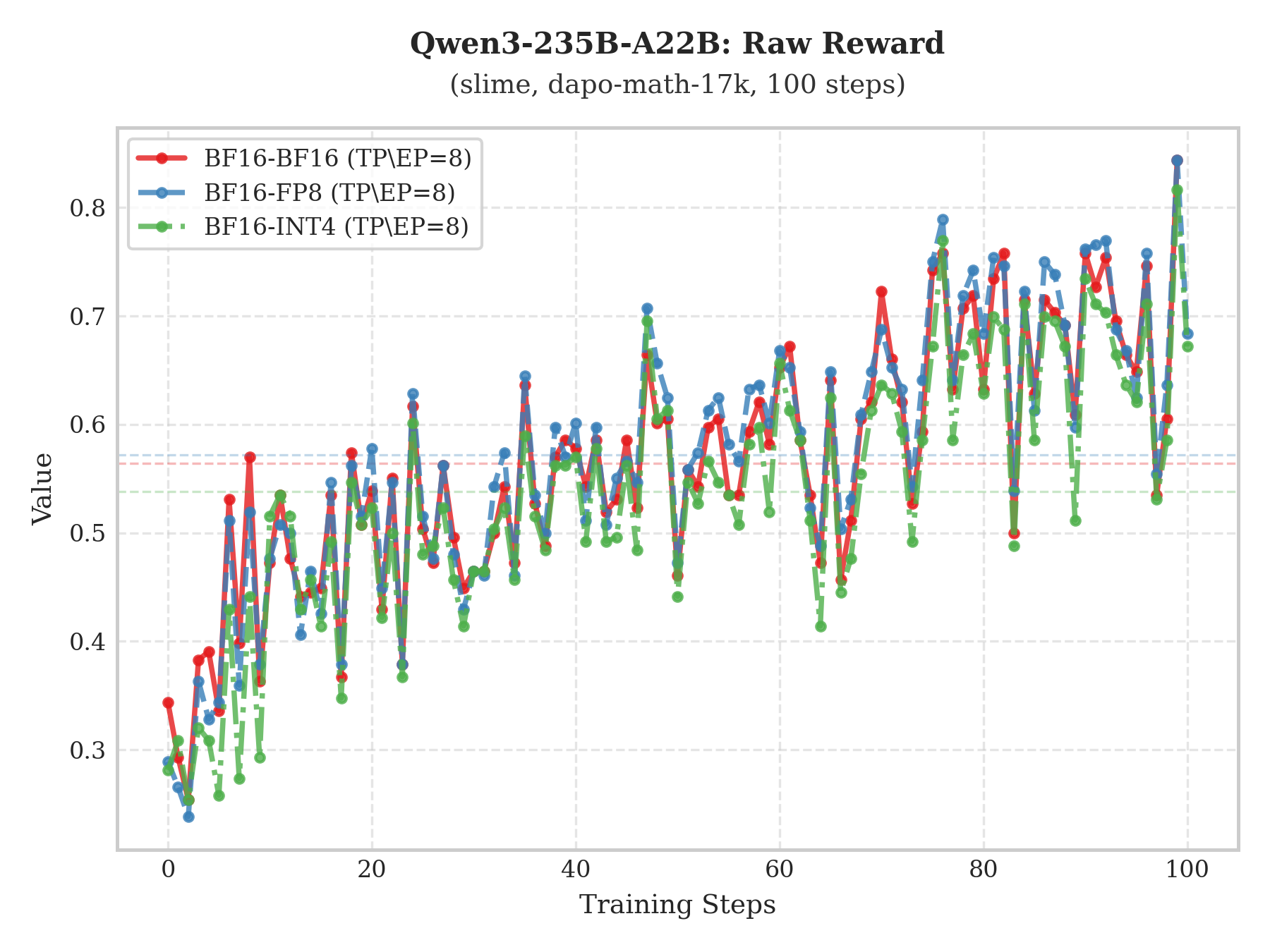
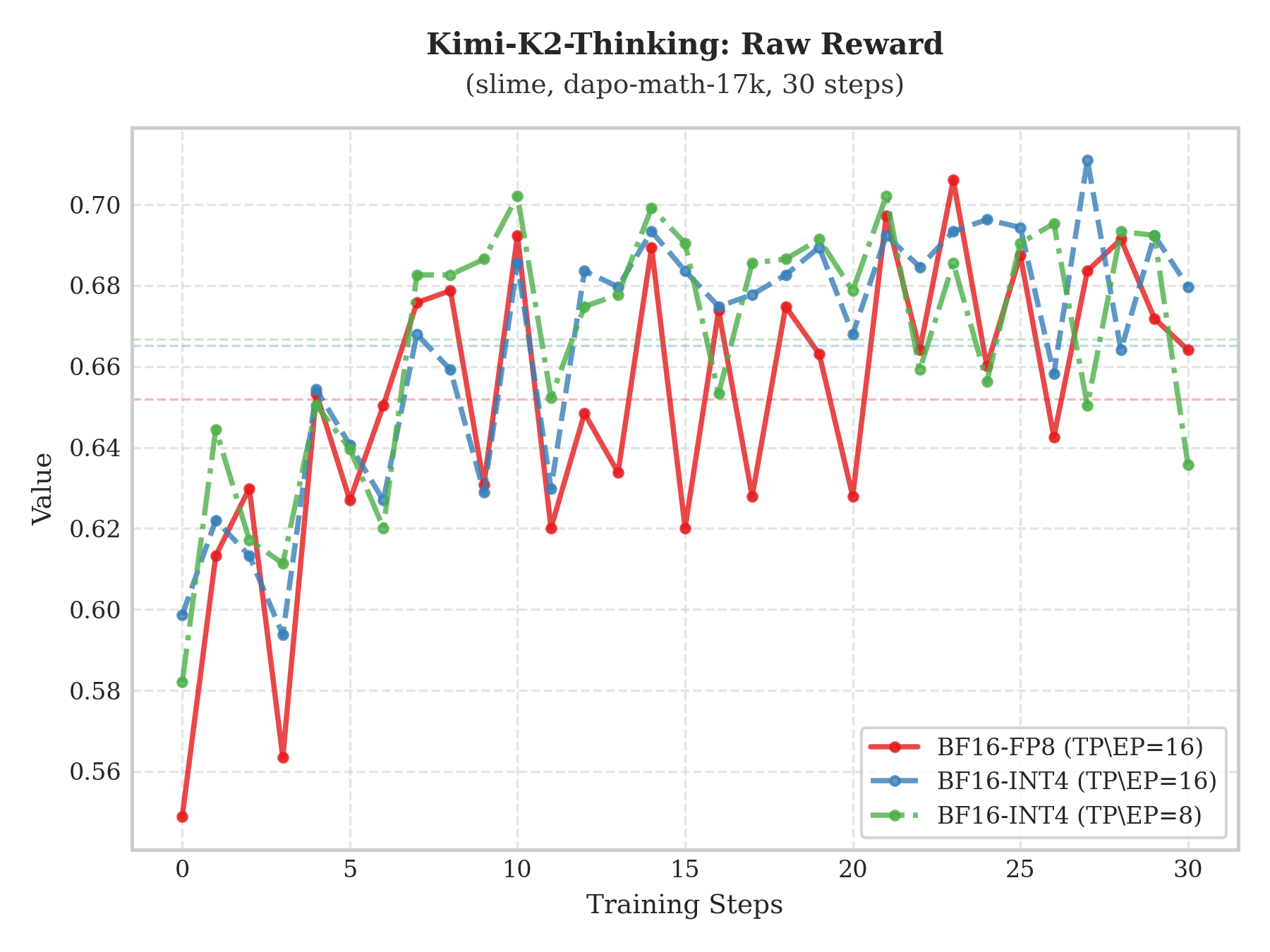
The plots above show training performance on the dapo-math-17k dataset for Qwen3-235B-A22B and Kimi-K2-Thinking under the slime framework. Compared with “BF16 train–BF16 infer” and “BF16 train–FP8 infer”, the “BF16 train–INT4 infer” setup still achieves steady Raw-Reward growth with a trend largely consistent with the former two, demonstrating the effectiveness of this approach.
- Evaluation side
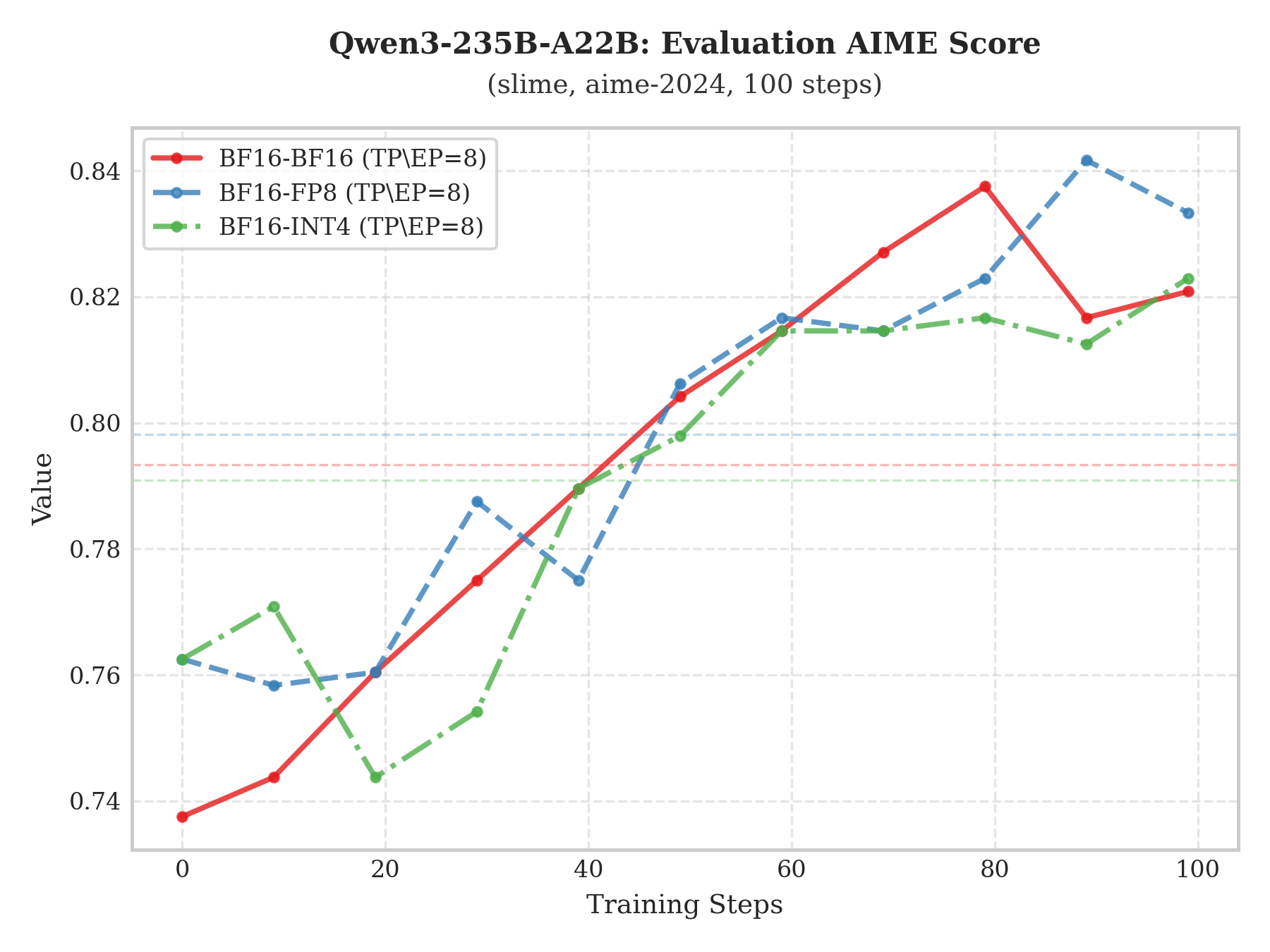
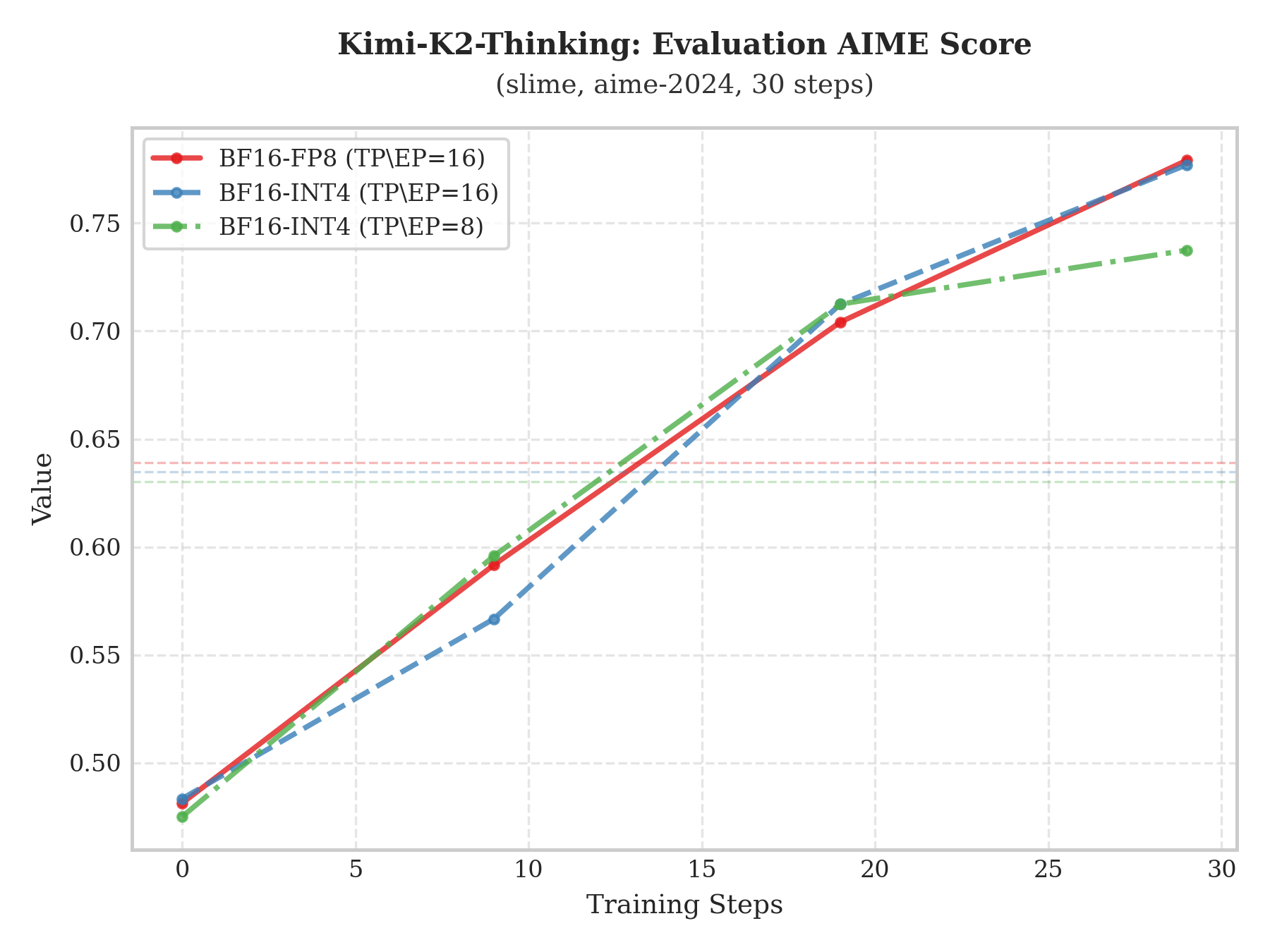
To evaluate model capability more rigorously, we run an evaluation on the aime-2024 benchmark every 10 training steps. The plots show the scoring trajectories of Qwen3-235B-A22B and Kimi-K2-Thinking under different RL training configurations.
The experiments indicate that the “BF16 train–INT4 infer” scheme not only exhibits a stable upward trend in evaluation scores, but also closely overlaps with “BF16 train–BF16 infer” and “BF16 train–FP8 infer” in both slope and peak score. This strong alignment suggests that low-bit quantization does not harm core representational capacity, enabling large compute savings while preserving (or matching) full-precision generalization performance.
Train–Infer Gap
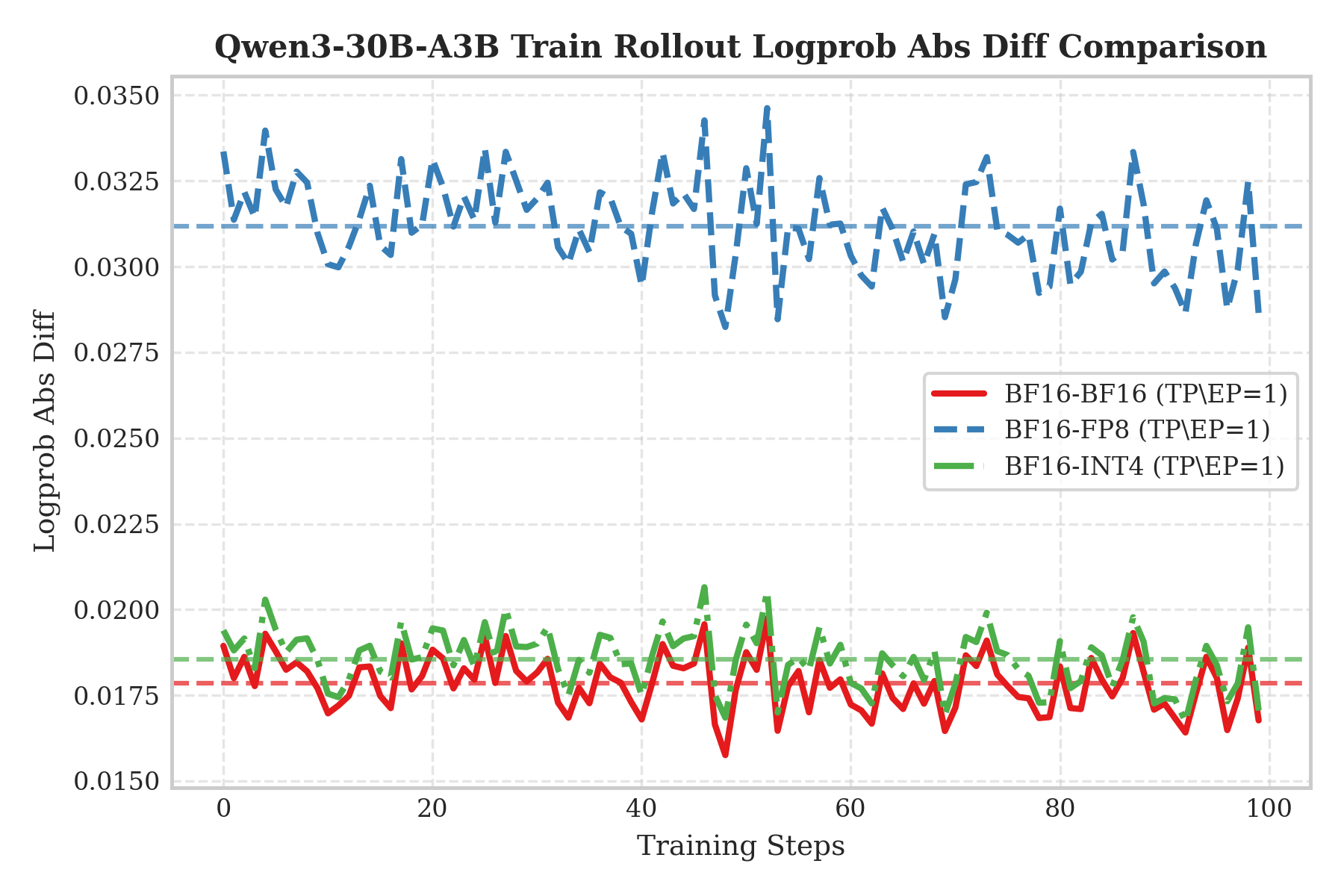
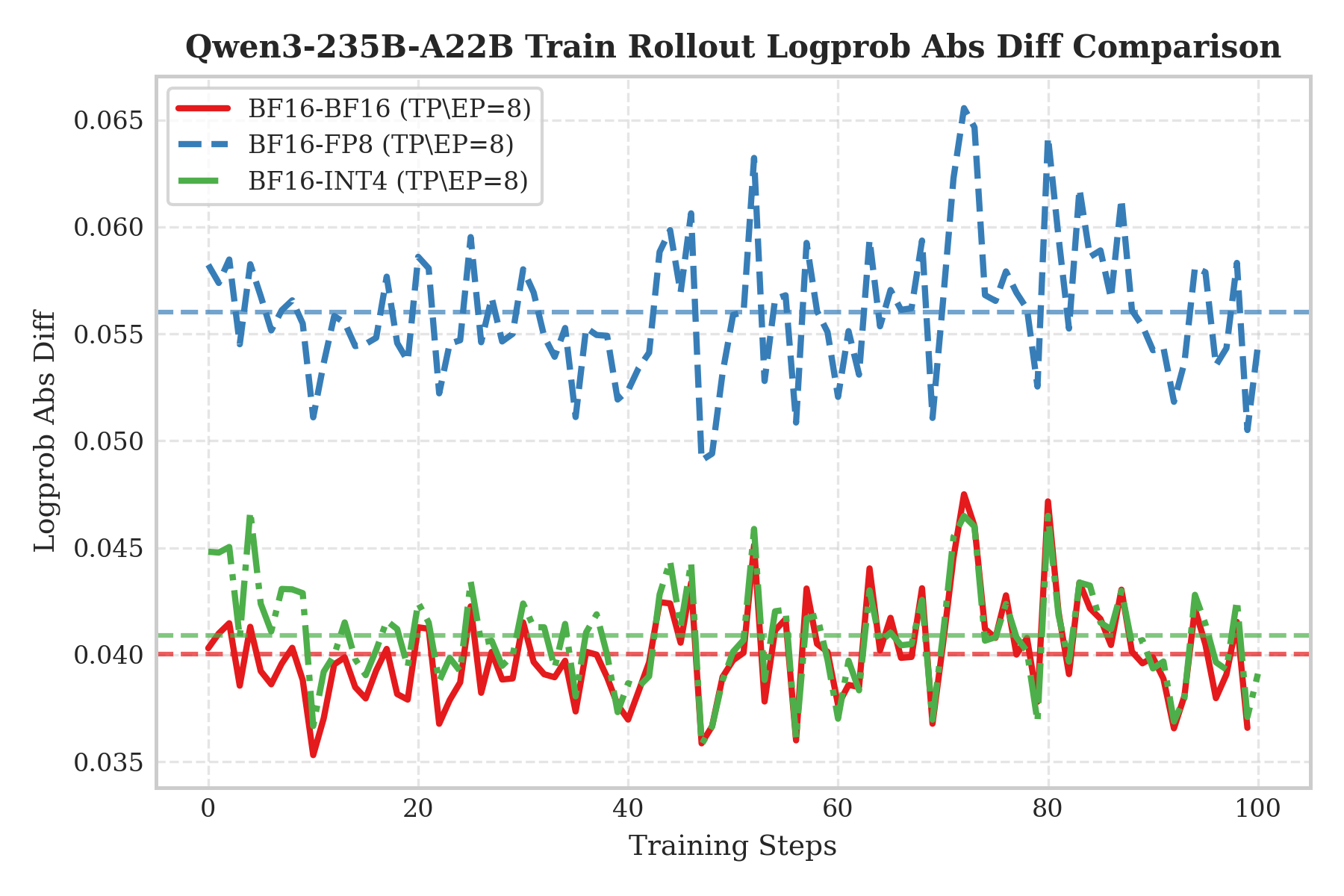
To visualize effectiveness, we validated QAT RL training on Qwen3-30B and Qwen3-235B. The Y-axis shows the absolute logprob difference between training-side and inference-side outputs; lower values mean stronger consistency. Results show that INT4 (green dashed) almost overlaps with the BF16 baseline (red solid), and is significantly lower than FP8 (blue dashed). This confirms that INT4 QAT can effectively avoid the accuracy loss in the “BF16 train–FP8 infer” mode and achieve train–infer behavior indistinguishable from full precision.
We hypothesize two reasons behind this consistency:
- Truncation error suppression: Training-side fake quantization constrains weights to the INT4 range. This constraint can effectively reduce floating-point rounding errors caused by non-deterministic accumulation orders in parallel matmul (i.e., the “adding a small number to a large number” precision loss).
- High-precision compute: Inference uses W4A16 and relies on BF16 Tensor Cores throughout, keeping compute precision highly aligned with training.
Rollout Speedup
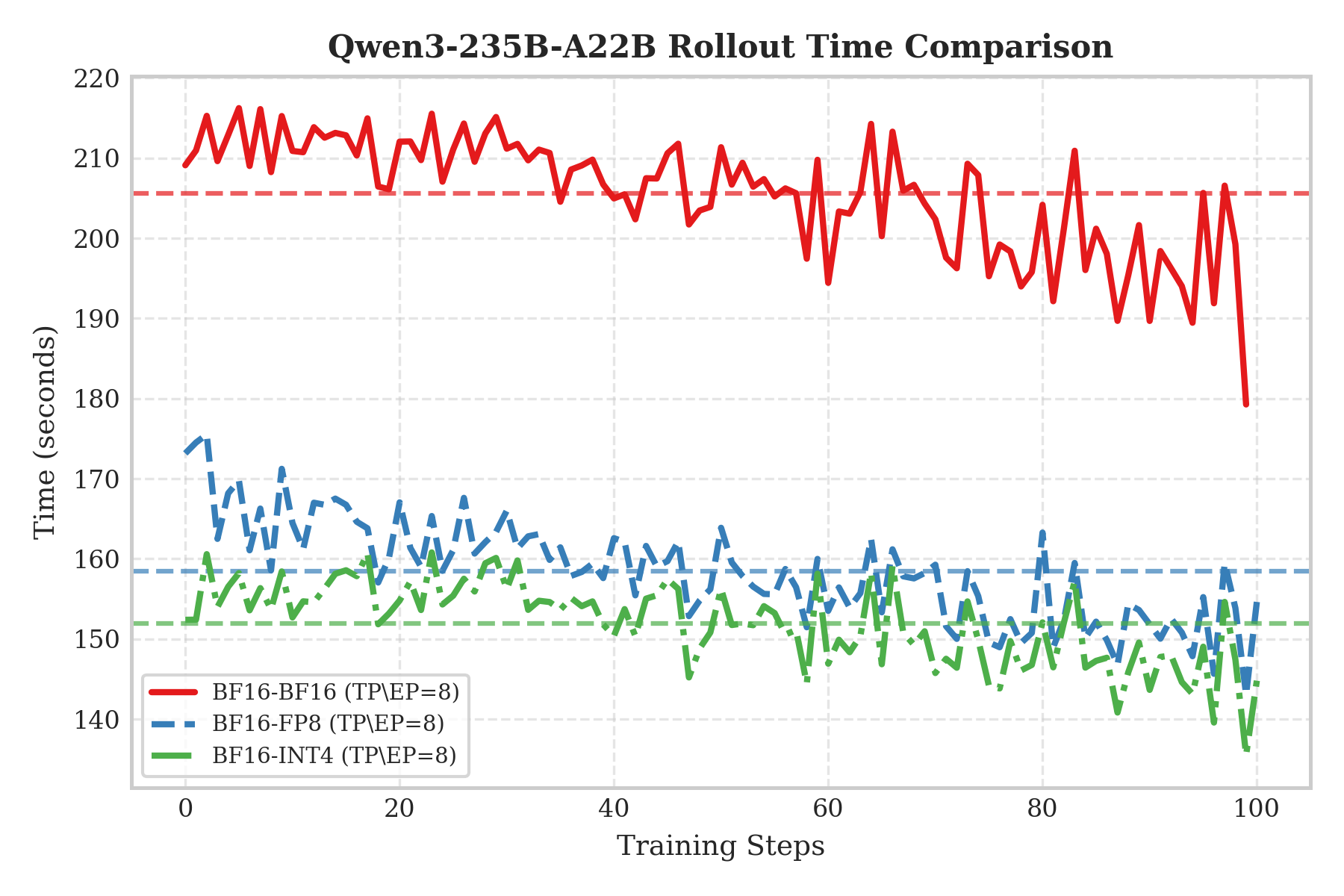
From the Qwen3-235B rollout performance plot, we can see that INT4 (green dash-dot) and FP8 (blue dashed) both significantly speed up compared to the BF16 baseline (red solid), but the gap between INT4 and FP8 is not huge. This is largely limited by current hardware: NVIDIA H-series GPUs do not have native INT4 Tensor Cores. W4A16 essentially still uses BF16 Tensor Cores for compute; while it greatly reduces memory bandwidth pressure, it cannot gain the compute uplift of native FP8 Tensor Cores as W8A8 does. Therefore, INT4 only shows a slight advantage in per-step latency and remains in roughly the same performance tier as FP8.
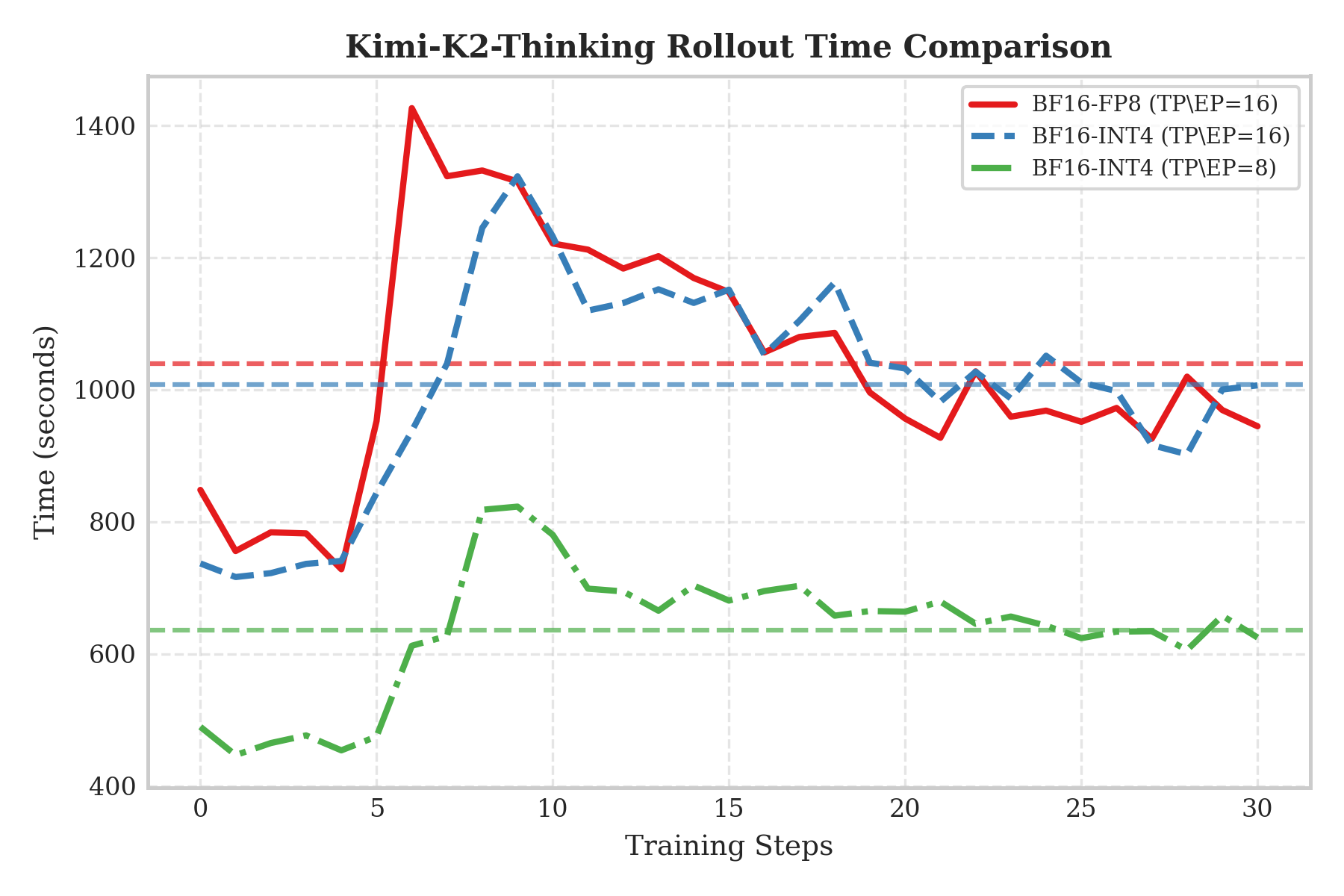
For Kimi-K2-Thinking rollout performance, first look at the communication bottleneck in the two-node scenario: FP8 (red line) and INT4 (blue line) are similar, because H-series GPUs lack native INT4 compute units and INT4 cannot speed up compute, so overall performance is still limited by cross-node bandwidth.
However, the single-node result (the green line) reveals INT4’s true value—VRAM compression. By halving model size, we can load ~1TB-scale models fully into a single machine’s VRAM, eliminating expensive cross-node communication and greatly reducing rollout time. This strongly demonstrates that under current hardware, the main benefit of INT4 QAT is enabling efficient single-node rollouts via VRAM compression.
Summary and Future Work
By reproducing the approach in an open-source framework, we validated the effectiveness of the INT4 QAT scheme proposed by the Kimi team:
- Accuracy reproduction: In slime reproductions, we observed the same INT4 QAT accuracy advantages, matching the BF16 baseline.
- Efficiency improvement: Rollout throughput improved significantly, validating the value of low-bit quantization in RL.
Future work:
- Training-side efficiency optimization: Today, adding QAT fake quantization introduces extra compute overhead during training, making it noticeably slower than BF16. This partially offsets the end-to-end gains from faster rollout. We plan to propose a new optimization to address this training-side bottleneck and accelerate the full pipeline.
- Inference-side FP4: As NVIDIA Blackwell becomes more widely available, we will actively explore FP4 precision for RL training and inference to further tap into hardware potential.
slime’s attempt at INT4 QAT not only demonstrates the feasibility of reproducing industrial state-of-the-art techniques in an open-source ecosystem, but also opens a new path for low-cost training at extreme scale. We hope this solution helps more developers deeply understand QAT and promote its practical adoption in RL.
Acknowledgements
SGLang RL Team: Ji Li, Yefei Chen, Xi Chen, BBuf, Chenyang Zhao
InfiXAI Team: Mingfa Feng, Congkai Xie, Shuo Cai
Ant Group Asystem & AQ Infra Team: Yanan Gao, Zhiling Ye, Yuan Wang, Xingliang Shi
slime Team: Zilin Zhu, Lei Li, Haisha Zhao