EPD Disaggregation: Elastic Encoder Scaling for Vision-Language Models in SGLang
TL;DR
We introduce Encoder-Prefill-Decode (EPD) Disaggregation in SGLang, a novel architecture that separates vision encoding from language processing in Vision-Language Models (VLMs). This can enable:
- Independent scaling of vision encoding capacity: Encoder servers can be scaled horizontally without affecting language model deployment, enabling better resource utilization for vision-heavy workloads.
- Compatibility with existing PD disaggregation: EPD can be combined with Prefill-Decode disaggregation for a complete three-tier architecture.
- Flexible transfer backends: Support for multiple transfer mechanisms (ZMQ, GPU-direct via Mooncake) allows optimization for different deployment scenarios.
- Vision embedding caching: Frequently used images can be cached at encoder servers, eliminating redundant ViT computations and reducing network transfer overhead.
EPD is highly effective in image-heavy scenarios (e.g., multi-image inputs), where the visual encoding process is the primary computational bottleneck. For instance, in these scenarios, we leverage EPD to significantly reduce request TTFT under load—achieving approximately 6–8× lower latency compared to the colocation approach at 1 QPS. Conversely, for image-light scenarios with few images, EPD may be less efficient or even counterproductive. This is because the additional network latency incurred by transmitting embeddings across nodes can outweigh the time saved by offloading the encoding task, potentially resulting in a higher TTFT compared to a colocation approach.
Introduction
Vision-Language Models (VLMs) like Qwen2.5-VL and Llama-Vision combine visual understanding with language generation. However, these models face unique scaling challenges:
- Heterogeneous compute needs: Vision encoding (CNN/ViT) requires different computational patterns than language decoding (Transformer)
- Imbalanced resource usage: Vision processing is compute-intensive but only needed during prefill
- Limited flexibility: Traditional monolithic deployments can't independently scale vision and language components
- Intra-request parallelism: Different images in one request can be encoded independently.
- Poor scaling under tensor parallelism: Because the vision encoder has far fewer parameters than the language component, applying tensor parallelism to it is inefficient and generally unnecessary.
SGLang's existing Prefill-Decode (PD) disaggregation already separates prefill from decode phases. EPD extends this by further separating vision encoding from language prefill, creating a three-tier architecture.
The ViT Scaling Problem: Why Tensor Parallelism Doesn't Always Help
The Counter-Intuitive Finding
One of the key insights from EPD disaggregation is that Vision Transformers (ViT) do NOT benefit from increased Tensor Parallelism, and can actually become slower with higher TP:
Benchmark on H20 with Qwen2.5-VL-72B (4 images per request):
| tp | vit mean time |
|---|---|
| 2 | 492.13ms |
| 4 | 465.80ms |
| 8 | 523.80ms |
Why Does This Happen?
- Communication overhead dominates execution time.
- The weight parameters of vision models are usually small.
EPD sidesteps this by scaling encoders horizontally instead of increasing TP.
Architecture Overview
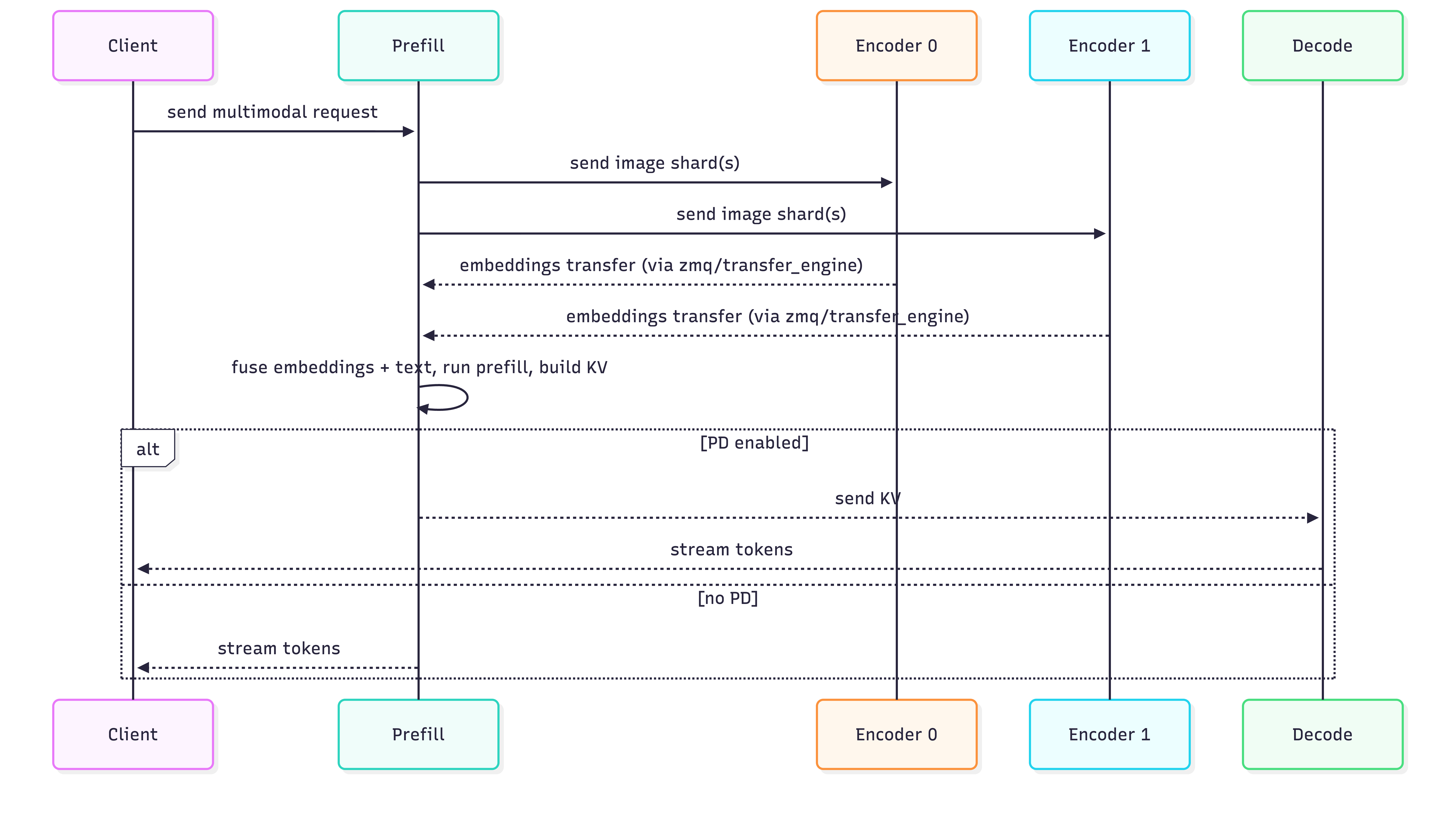
The EPD architecture follows a request flow:
- Client Request: A multimodal request arrives at the prefill server (via load balancer or direct connection).
- Image Distribution: The prefill server identifies image inputs and distributes them to one or more encoder servers. Images can be split across multiple encoders for load balancing.
- Vision Encoding: Encoder servers process images through ViT, generating vision embeddings and image grid metadata. Results are cached if enabled.
- Embedding Transfer: Vision embeddings are transferred back to the prefill server using the configured transfer backend (ZMQ, Mooncake, etc.).
- LLM Computation: The prefill server combines vision embeddings with text tokens to form mm_inputs containing pre-computed tensors. The LLM performs Prefill and Decode computation based on these embeddings. If PD disaggregation is enabled, the existing Prefill-Decode transfer logic is reused; otherwise, token generation happens directly on the prefill server.
Key Components

Encoder Server (--encoder-only)
- Vision-only (no language weights); preprocessing + ViT forward to generate vision embeddings
- Prefix multimodal cache support
- Scale out for load balancing and parallel multi-image split inference
Prefill Server (--language-only)
- Language model only
- Receives embeddings from encoder(s)
- With PD: ships KV to Decode; without PD: decodes locally
Decode Server
- Standard decode-only instance
- Receives KV cache from prefill
Implementation Details
Image Distribution Strategies
Unlike tensor parallelism which splits a single model across GPUs, EPD uses data parallelism by running multiple independent encoder instances and distributing images among them.
Example distribution:
Request with 7 images: [img0, img1, img2, img3, img4, img5, img6]
3 encoders available
Distribution (after shuffle):
├─ Encoder 0: [img0, img1, img2] (3 images)
├─ Encoder 1: [img3, img4] (2 images)
└─ Encoder 2: [img5, img6] (2 images)
Transfer Backends
EPD supports three transfer backends for vision embeddings:
zmq_to_scheduler (Default)
- Direct ZMQ socket communication
- Embeddings sent from encoder to scheduler via RDMA transfer engine.
- No blocking
zmq_to_tokenizer
- Embeddings sent to tokenizer manager
- Processed during tokenization phase
mooncake
- RDMA-based transfer for multi-node
- Registers embeddings in shared memory
- High-bandwidth, low-latency transfer
Vision Embedding Cache
The encoder supports prefix multimodal caching to avoid redundant ViT computations:
- Eliminates redundant vision encoding
- Reduces latency for repeated images
- Configurable cache size (default 4GB via SGLANG_VLM_CACHE_SIZE_MB)
Usage Examples
- To launch the encoder instance
MODEL=Qwen/Qwen2.5-VL-7B-Instruct
PORT=30002
CUDA_VISIBLE_DEVICES=2 taskset -c $1 python -m sglang.launch_server \
--model-path $MODEL \
--encoder-only \
--enable-prefix-mm-cache \
--port $PORT
- To launch the prefill instance
MODEL=Qwen/Qwen2.5-VL-7B-Instruct
PORT=30000
TP=1
MEM_FRACTION=0.5
CHUNK_SIZE=8192
SGLANG_VLM_CACHE_SIZE_MB=0 CUDA_VISIBLE_DEVICES=0 python -m sglang.launch_server \
--model-path $MODEL \
--disaggregation-mode prefill \
--disaggregation-transfer-backend nixl \
--tp $TP \
--mem-fraction-static $MEM_FRACTION \
--disable-radix-cache \
--chunked-prefill-size $CHUNK_SIZE \
--language-only \
--encoder-urls http://127.0.0.1:30002 http://127.0.0.1:30003 http://127.0.0.1:30004 http://127.0.0.1:30005 http://127.0.0.1:30006 http://127.0.0.1:30007 \
--port $PORT
- To launch the decode instance
MODEL=Qwen/Qwen2.5-VL-7B-Instruct
PORT=30001
TP=1
CUDA_VISIBLE_DEVICES=1 python -m sglang.launch_server \
--model-path $MODEL \
--disaggregation-mode decode \
--disaggregation-transfer-backend nixl \
--tp $TP \
--port $PORT
- To launch minlb
python -m sglang_router.launch_router \
--pd-disaggregation \
--mini-lb \
--prefill http://127.0.0.1:30000 \
--decode http://127.0.0.1:30001 \
--port 8000
Benchmark
EPD disaggregation targets vision-heavy workloads (multi-image requests) and improves Time To First Token (TTFT) by scaling encoder servers horizontally. Launch bench script:
python -m sglang.bench_serving \
--random-image-count \
--model ${MODEL_PATH} \
--num-prompts 64 \
--dataset-name image \
--random-input-len 128 \
--random-output-len 256 \
--image-count 8 \
--image-resolution 1080p \
--host $HOST_IP \
--port $port \
--backend vllm-chat \
--request-rate $request_rate
Experimental Setup
Environment: 8× H20 96GB GPUs
Model: Qwen3-VL-235B-A22B-Instruct-FP8
Dataset: Random multimodal dataset
- Text tokens: 128 / 256
- Images per request: 1-8 images (random count, average ~4 images)
- Image resolution: 1080p
- QPS range: 0.2-1.0
Deployment Configurations:
- Colocate: 1 PD instance with tensor-parallel-size=4, uses 4× H20 GPUs
- 1E1P (1 Encoder + 1 PD instance): 1 Encoder with tensor-parallel-size=1 + 1 PD instance with tensor-parallel-size=4, uses 5× H20 GPUs
- 2E1P (2 Encoders + 1 PD instance): 2 Encoders with tensor-parallel-size=1 each + 1 PD instance with tensor-parallel-size=4, uses 6× H20 GPUs
Bench Results
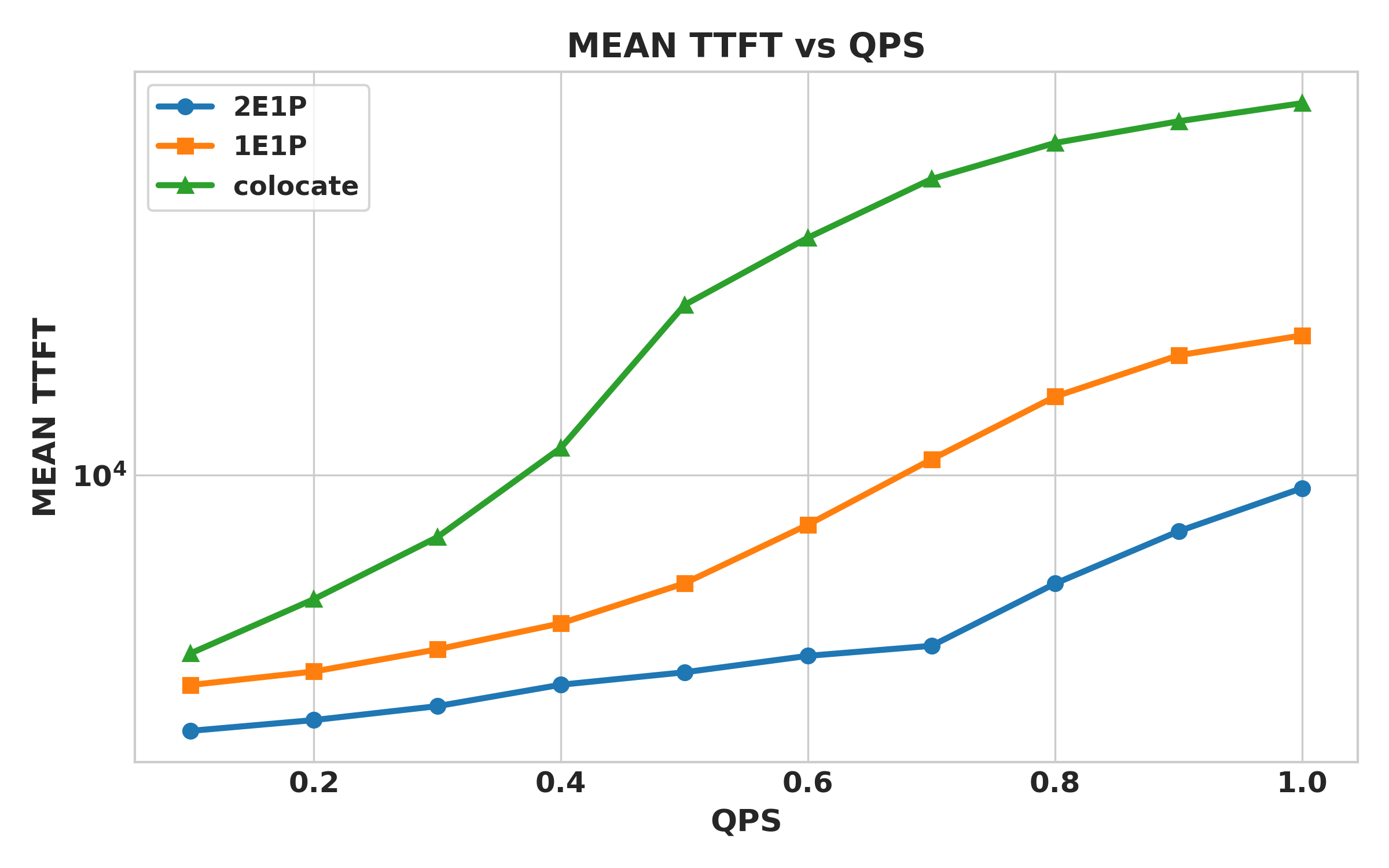
Mean TTFT (EPD vs colocate)
Mean TPOT (EPD vs colocate)
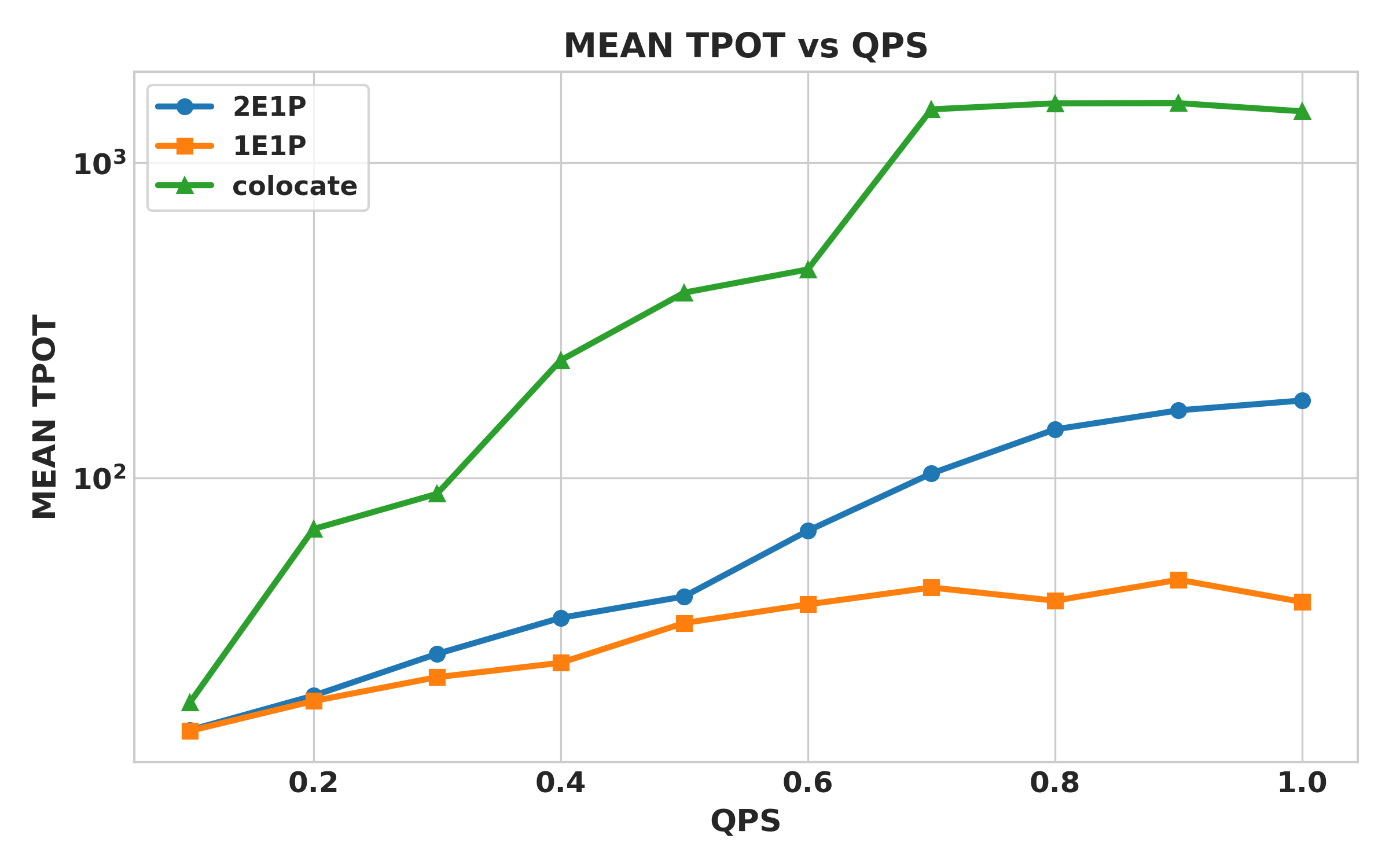
The higher TPOT observed in 2e1p is attributed to its larger batch size during decoding.
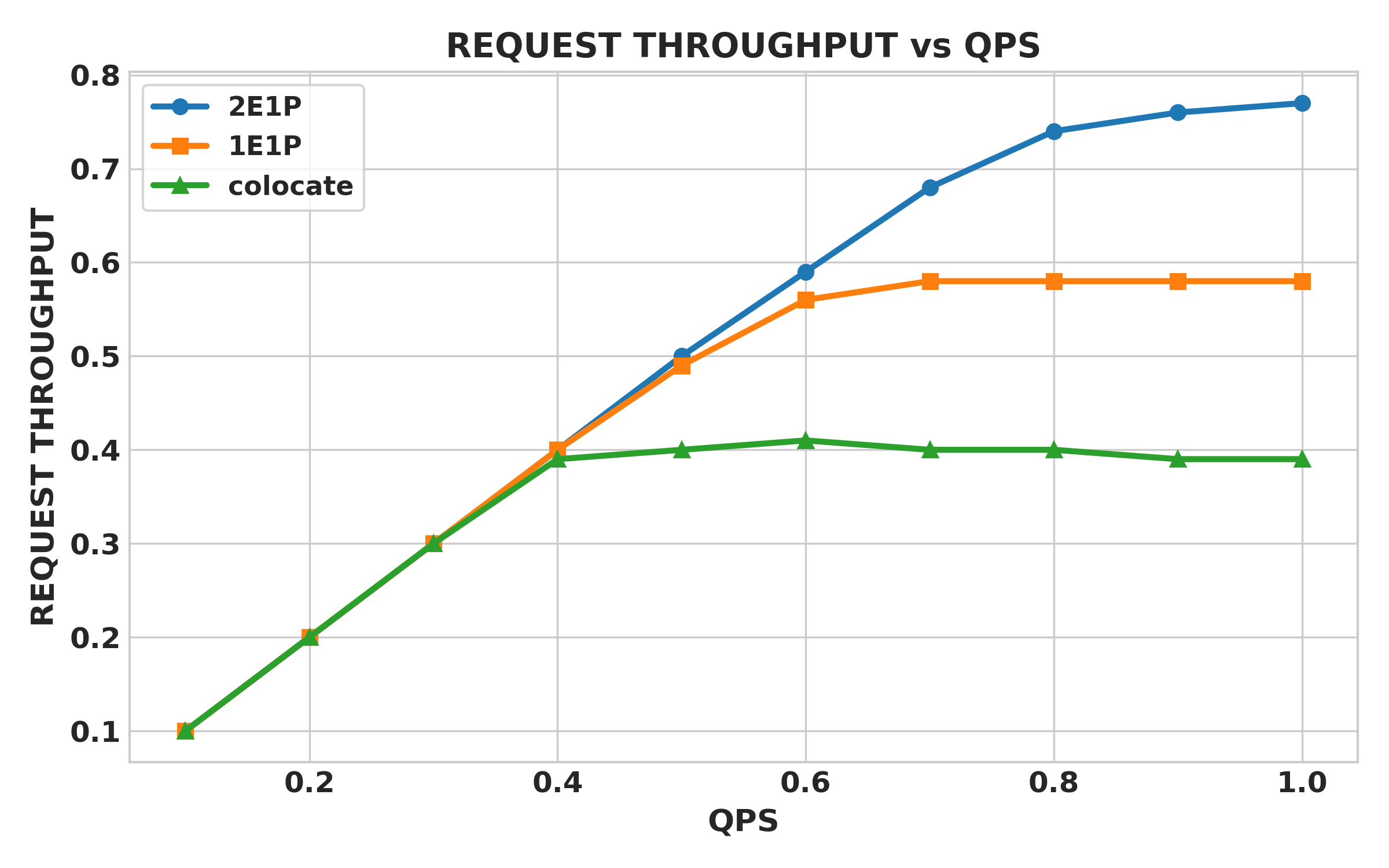
Request Throughput (EPD vs colocate)
Key Findings (vs. colocate)
- Encoder/prefill keeps TTFT much lower under load (≈6–8x lower than colocate at 1 qps).
- TPOT stays far below colocate (≈8–10x lower), indicating much tighter latency.
- Throughput roughly doubles at higher QPS (≈2x at 0.8–1.0 qps vs. colocate).
- The dramatic reduction in TTFT is achieved by allocating dedicated GPU resources to the encoder. Despite using 50% additional GPUs (2E1P uses 6× H20 vs. colocate's 4× H20), EPD disaggregation achieves a much higher return on investment (ROI) compared to simply scaling the traditional integrated architecture, with performance gains exceeding the additional resource cost.
- While highly effective for image-heavy tasks, dedicated encoder GPUs may experience lower utilization (idle time) in image-light scenarios, suggesting that EPD is most resource-efficient when visual processing is the primary bottleneck.
Acknowledgment
rednote hilab: Tianyu Guo, a'du, Tianming Xu
Alibaba Cloud Computing: Siyu Liu, Shangming Cai
AntGroup SCT: Wengang Zheng
Learn more
- Roadmap: Encoder Disaggregation (2025 Q4)